深度学习之图像分类(二十七)ConvMLP网络详解
是传统 CNN 还是 MLP?大家一起来看看这个所谓的层次卷积 MLP。不可否认其在实验上很充分,考虑了下游任务,给出了预训练模型,但是其在网络上的真实贡献可以说“微乎其微”…

1. 前言
不到一个月前(2021.9.18),UO&UIUC 提出了 ConvMLP:一个用于视觉识别的层次卷积MLP。作为一个轻量级(light-weight)、阶段级(stage-wise)、具备卷积层和MLP的联合设计(co-design),ConvMLP 在 ImageNet-1k 上以仅仅 2.4G MACs 和 9M 参数量 (分别是 MLP-Mixer-B/16 的 15% 和 19%) 达到了 76.8% 的 Top-1 精度。其论文为 ConvMLP: Hierarchical Convolutional MLPs for Vision,代码也放到了 Github。
老生常谈,纯 MLP 架构的问题在于:
- 很难将其应用于下游任务,如目标检测和语义分割;
- 此外,单阶段(输入输出尺寸完全一致)的设计进一步限制了其他计算机视觉任务的性能(ViP,AS-MLP 等注意到多阶段会进一步提升性能);
- 连续的全连接层具有较大的计算量。
为了解决这些问题,作者提出了 ConvMLP:
- 用卷积替换 token-mixing mlp,使得网络对输入尺寸不敏感,从而解决第一个问题;
- 用类似 Swin 等等工作使用的卷积下采样(stride = 2)实现多阶段;
- 从 DW Conv(group = channel)实现低参数量和计算量,解决第三个问题。
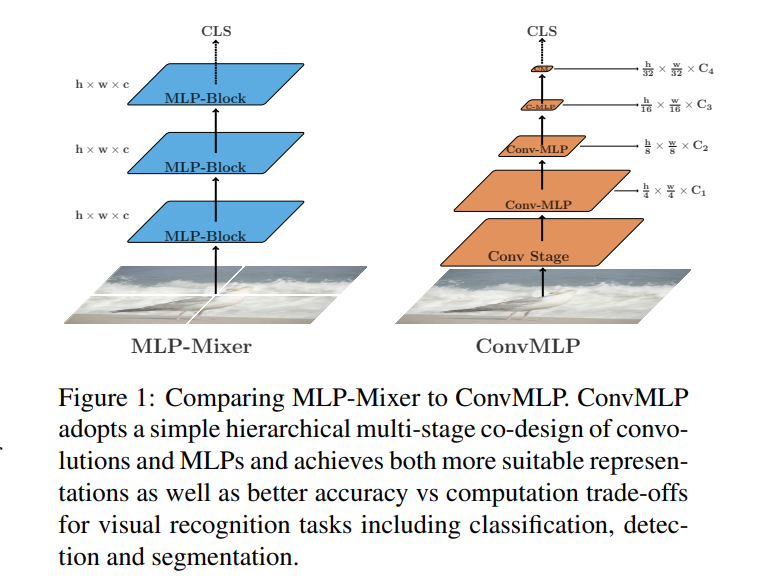
最终网络在 ImageNet 上的性能对比结果如下所示:
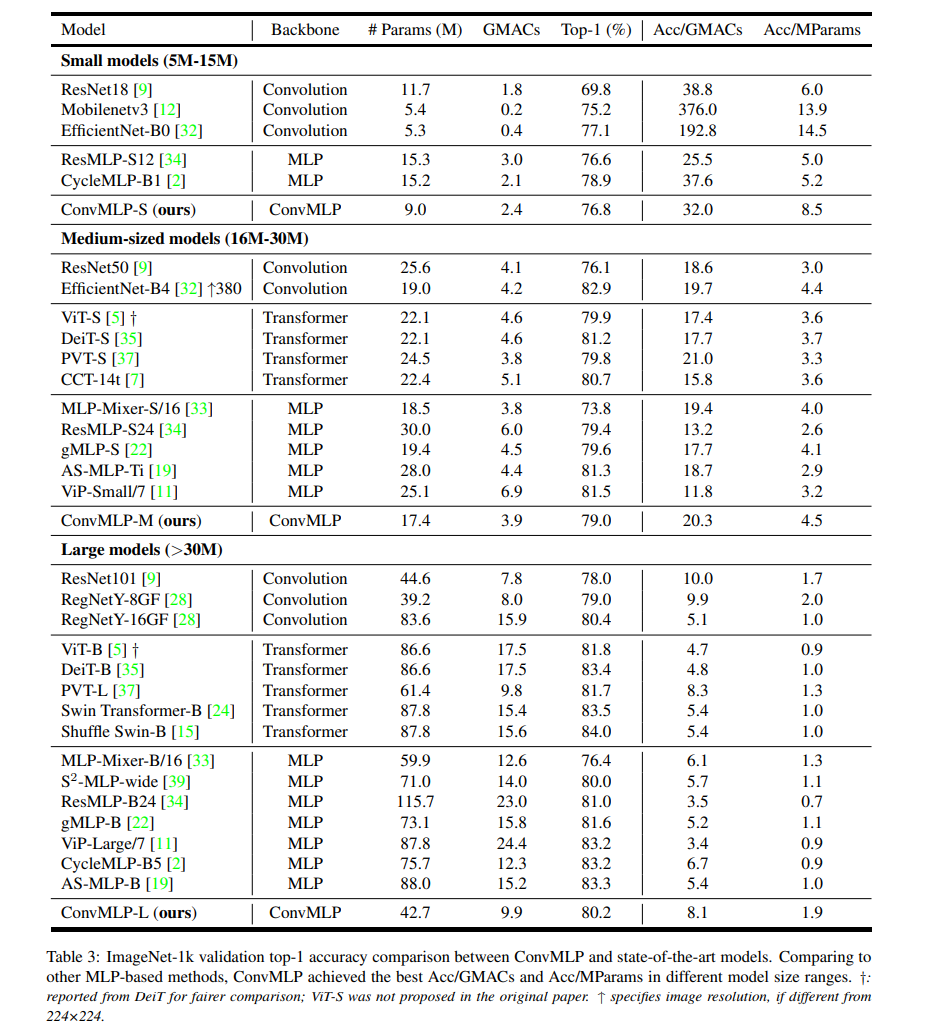
2. ConvMLP: CNN or MLP?
在 AS-MLP,S2MLP 等网络学习中,我脑海中一直有一个终极问题:既然想要引入局部性,又取消了 Token-mixing MLP,为啥宁愿移动特征图再使用 $1 \times 1$ 卷积构造局部感受野也不使用 $3 \times 3$ 卷积呢?可能使用卷积了,就不能炒 MLP 的概念了…
“老实人”出现了,ConvMLP 使用 $3 \times 3$ DW 卷积来替换 Token-mixing MLP,以引入局部性特征,然后说是 MLP。这不,引来了我的质疑…
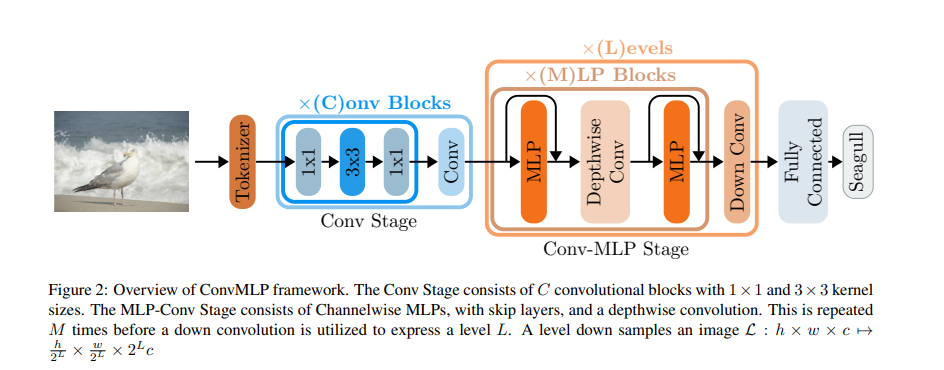
让我们一步一步梳理网络的结构,并对应源码进行分析。
2.1 Convolutional Tokenizer
Convolutional Tokenizer 是我比较喜欢的点。ConvMLP 工作给我的惊喜之一就是在 Related Work 中告诉了我 CCT 提出了Convolutional Tokenizer 替换 Patch Embedding 并提高了性能。在上一文讲解 ConvMixer 之后,我一直有个思考:Patch Embedding(kernel size = stride = patch size 的卷积)其实就是等价于传统的 CNN(kernel size = patch size, stride = 1 的卷积加上 pooling size = patch size 的池化),借由 VGGNet 的思想,大卷积核的卷积进一步可以拆分为连续 $3 \times 3$ 卷积,且大的 pooling 也可以被细化为多个小的 pooling 放到卷积层中间。所以 Patch Embedding 其实可以被视作一种减少计算量的简单直接做法,并不特殊,可能还没有原来的 stride = 1 的好。这不,Convolutional Tokenizer 出来了(YX所见略同啊)。
ConvMLP 中 Convolutional Tokenizer 的具体实现非常简单:例如一个 $224 \times 224 \times 3$ 的自然图像作为输入,经过三个 $3 \times 3$ 的卷积,BN 和 ReLU,最后经过一个池化层就结束了。值得注意的是第一个卷积层的 stride = 2,最后有一个 stride = 2,kernel size = 3 的最大池化。这样之后得到的特征图长宽都变为了 1/4,通道数为 64,最终的特征图大小为 $56 \times 56 \times 64$。
class ConvTokenizer(nn.Module):
def __init__(self, embedding_dim=64):
super(ConvTokenizer, self).__init__()
self.block = nn.Sequential(
nn.Conv2d(3, embedding_dim // 2, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False),
nn.BatchNorm2d(embedding_dim // 2),
nn.ReLU(inplace=True),
nn.Conv2d(embedding_dim // 2, embedding_dim // 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
nn.BatchNorm2d(embedding_dim // 2),
nn.ReLU(inplace=True),
nn.Conv2d(embedding_dim // 2, embedding_dim, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
nn.BatchNorm2d(embedding_dim),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), dilation=(1, 1))
)
def forward(self, x):
return self.block(x)
2.2 Conv Stage
为了增加空间内的信息交互,作者采用了完全卷积的阶段。它由多个块组成,其中每个块由两个 $1 \times 1$ 卷积层组成,中间有一个 $3 \times 3$ 卷积层。(蓝色框所示),并进行了残差。(其实就是仿照 ResNet50)。最后再经过一个 stride = 2 的 $3 \times 3$ 卷积实现下采样。
class ConvStage(nn.Module):
def __init__(self,
num_blocks=2, embedding_dim_in=64, hidden_dim=128, embedding_dim_out=128):
super(ConvStage, self).__init__()
self.conv_blocks = nn.ModuleList()
for i in range(num_blocks):
block = nn.Sequential(
nn.Conv2d(embedding_dim_in, hidden_dim, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0), bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, embedding_dim_in, kernel_size=(1, 1), stride=(1, 1), padding=(0, 0), bias=False),
nn.BatchNorm2d(embedding_dim_in),
nn.ReLU(inplace=True)
)
self.conv_blocks.append(block)
self.downsample = nn.Conv2d(embedding_dim_in, embedding_dim_out, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
def forward(self, x):
for block in self.conv_blocks:
x = x + block(x)
return self.downsample(x)
至此为止,毫无疑问就是普通的 CNN。
2.3 Conv-MLP Stage
为了减少对输入维度的约束,作者用 Channel-mixing MLP ($1 \times 1$ 卷积)替换所有的 Token-mixing MLP。但是这样会导致缺少空间上信息的交互,因此作者通过添加卷积层来进行局部信息交互,以弥补空间交互的缺失。(橘色框所示)。
每个 Channel-mixing MLP 其实就是先经过 LN 归一化,然后两个通道方向的全连接层,GELU 激活函数。这其实可以看作就是 $1 \times 1$ 卷积。然后中间的卷积层使用 $3 \times 3$ 的 Depthwise Conv,弥补了空间信息的交互且只带来很少的参数。注意到:ConvMixer 坦诚地就说自己的 $1 \times 1$ 加 $3 \times 3$ 卷积是卷积神经网络,Block 是 ConvBlock,没有说自己是全连接。
此外,作者遵循了 Swin Transformer 中使用基于线性层的 patch 合并方法来对特征图进行下采样的设计方式。不同的是,作者用步长为 2 的 $3 \times 3$ 卷积层替换 patch 合并 (步长为 2 的 $2 \times 2$ 卷积),这使得下采样的时候,能够有空间信息的重叠。这提高了分类精度,同时也只引入了很少的参数。
class Mlp(nn.Module):
def __init__(self,
embedding_dim_in, hidden_dim=None, embedding_dim_out=None, activation=nn.GELU):
super().__init__()
hidden_dim = hidden_dim or embedding_dim_in
embedding_dim_out = embedding_dim_out or embedding_dim_in
self.fc1 = nn.Linear(embedding_dim_in, hidden_dim)
self.act = activation()
self.fc2 = nn.Linear(hidden_dim, embedding_dim_out)
def forward(self, x):
return self.fc2(self.act(self.fc1(x)))
class ConvMLPStage(nn.Module):
def __init__(self, embedding_dim, dim_feedforward=2048, stochastic_depth_rate=0.1):
super(ConvMLPStage, self).__init__()
self.norm1 = nn.LayerNorm(embedding_dim)
self.channel_mlp1 = Mlp(embedding_dim_in=embedding_dim, hidden_dim=dim_feedforward)
self.norm2 = nn.LayerNorm(embedding_dim)
self.connect = nn.Conv2d(embedding_dim, embedding_dim, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=embedding_dim, bias=False)
self.connect_norm = nn.LayerNorm(embedding_dim)
self.channel_mlp2 = Mlp(embedding_dim_in=embedding_dim, hidden_dim=dim_feedforward)
self.drop_path = DropPath(stochastic_depth_rate) if stochastic_depth_rate > 0 else nn.Identity()
def forward(self, src):
src = src + self.drop_path(self.channel_mlp1(self.norm1(src)))
src = self.connect(self.connect_norm(src).permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
src = src + self.drop_path(self.channel_mlp2(self.norm2(src)))
return src
class ConvDownsample(nn.Module):
def __init__(self, embedding_dim_in, embedding_dim_out):
super().__init__()
self.downsample = nn.Conv2d(embedding_dim_in, embedding_dim_out, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
def forward(self, x):
x = x.permute(0, 3, 1, 2)
x = self.downsample(x)
return x.permute(0, 2, 3, 1)
了解到了实现之后,让我们再来反思一下:ConvMLP 真的是 MLP 吗?
我认为不是!无非是将 ResNeXt 的 ResNeXt block 进行了一点点修改:
- 前后的单个 $1 \times 1$ 卷积替换为了两个 $1 \times 1$ 卷积,中间使用了 GELU 激活函数,且使用前 LN 归一化而非后 BN 归一化。
- 中间 $3 \times 3$ 卷积的 Group 数设定为通道数。
2.4 Classifier head
最后的分类器也是最普通的,归一化 + 全局池化 + 全连接。
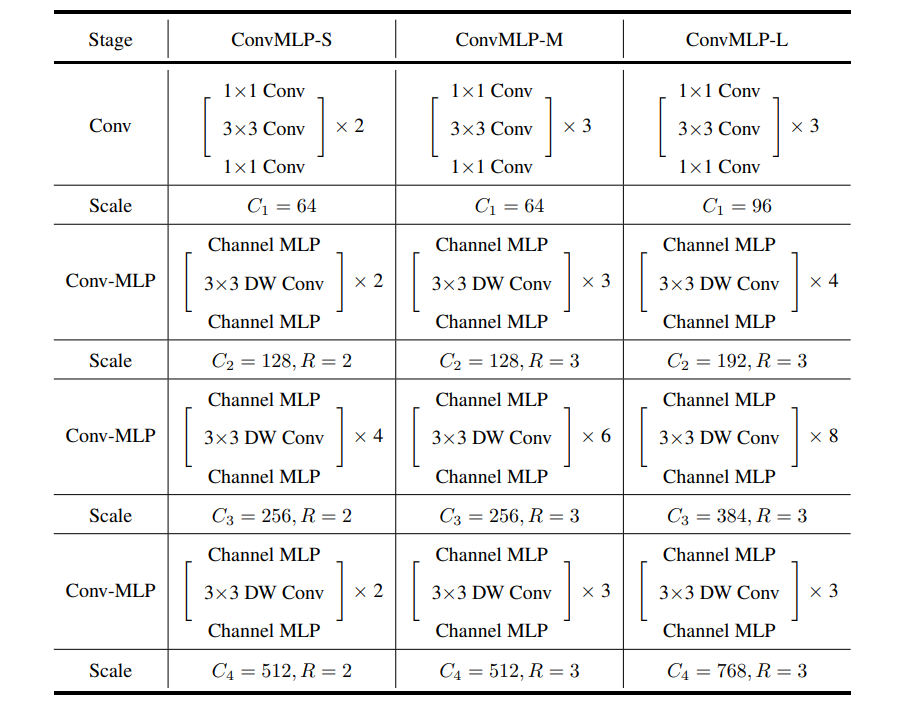
2.5 网络配置参数
作者给出了三种网络配置,ConvMLP-s,ConvMLP-m,ConvMLP-l,分别再宽度和深度上扩展了 ConvMLP。
3. Visualizations
本文实验给出了特征图的可视化,作者谈到【可以观察到,与 ResNet 相比,ConvMLP 学习的表示涉及更多的低级特征,如边缘或纹理,与 Pure-MLP 的baseline 相比,涉及更多的语义信息】,其中 Pure-MLP 表示没有 DW Conv。事实上在我看来,ResNet 的特征表示更加稀疏,MLP-Mixer 的特征图难以解释。而其 ConvMLP 的中间特征图感觉噪声信息比较严重?

作者进一步给出了一些 ImageNet 训练好后,网络的误分类输入的激活图( Salient Maps)进行分析,可见 MLP-Mixer 尽管有时候分类正确,但是关注的地方很大,应该是过拟合。ResMLP 和 MLP-Mixer 都是像素块效应较为严重(缺乏重叠的信息交互)。相比而言,ConvMLP 似乎表现得更好一些。那,ResNet 呢?

4. 反思与总结
本文提出了 ConvMLP,虽然自称为 MLPs,但是我个人不敢苟同。我觉得更像把 MLP 中使用的 Channel-MLP (LN 前归一化,两个 $1 \times 1$ 卷积加 GELU) 替换 CNN 中的 $1 \times 1$ 卷积 + BN + ReLU。然后把 $3 \times 3$ Group Conv 的组数设定为通道数,仅此而已。那么这样看起来,这就是一个 CNN…
作为一个 CNN,在 ImageNet 上进行训练,然后试试看其迁移到 Cifar10,Cifar100,Flower-102 上的性能是基本操作。
作为一个 CNN,在 ImageNet 上进行训练,然后取其 backbone 放到 COCO 也是基本操作。
那么基于此,它并不比 EfficientNet 出色,更不说 EfficientNetV2。
不可否认本文实验做得很多,也给出了 ImageNet 预训练参数,Mask R-CNN 和 RetinaNet 等参数。论文中某些描述和思想也可以被学习和借鉴。但是平心而论,就整个论文的贡献点而言并不多,想搭着 MLP 的东风其实也并不太成功(怕我自己没有理解清楚,在细读源码后,我个人依然将其评价为 ”最假“ MLP)。ConvMixer,ConvMLP,看似几个字母的不同,实则论文故事,贡献度,坦诚度也差了几个级。
5. 代码
代码片段已经在分析中提供了。我实现的 Pytorch 和 Jittor 版本见 此处。