深度学习之图像分类(三十一)CycleMLP网络详解
这应该是目前最后学习的一篇 MLP 架构的论文了,CycleMLP 其实和 AS-MLP 的思想基本一致,让我们来详细看看。

1. 前言
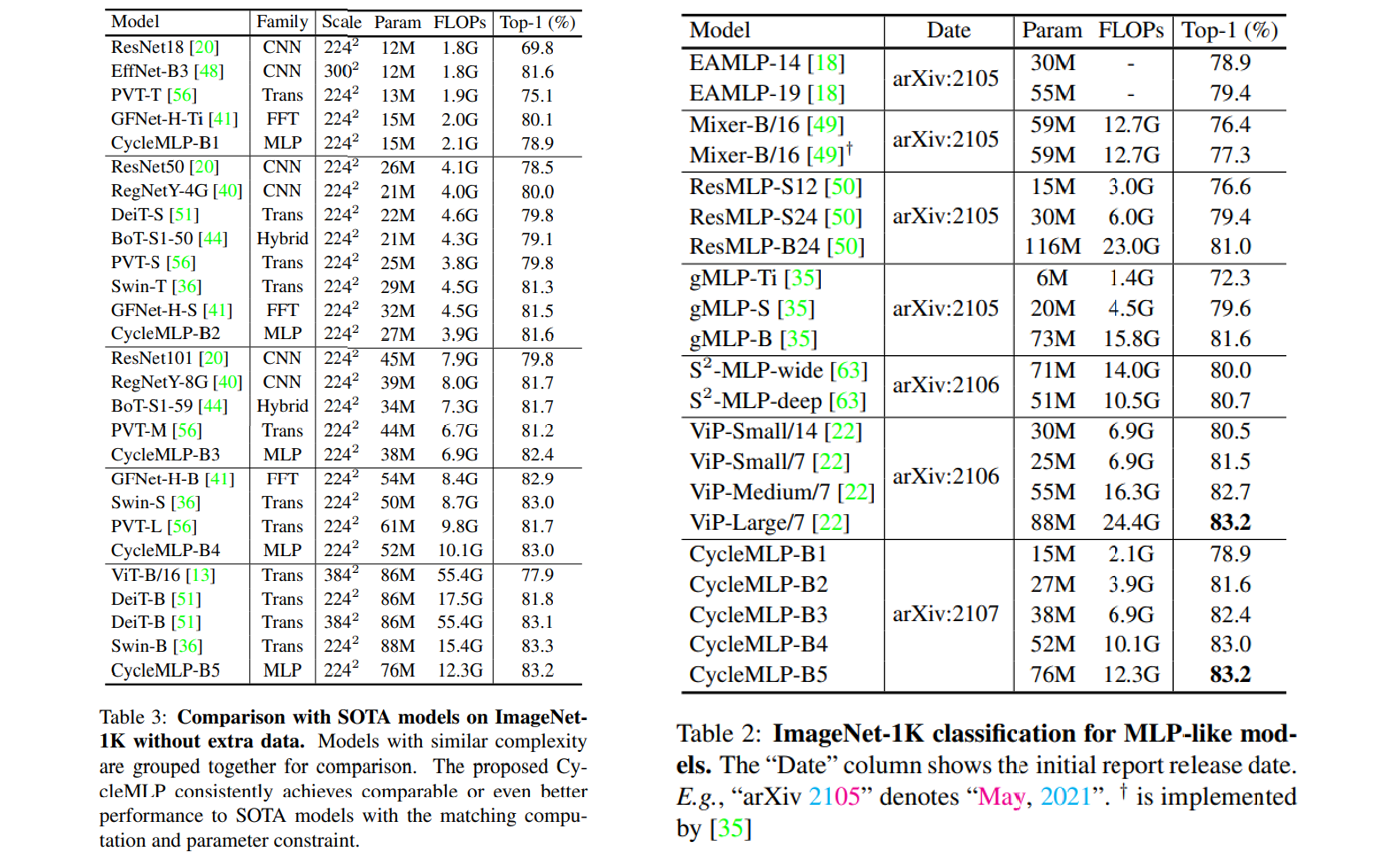
本此学习香港大学&商汤联合提出的 CycleMLP。这也是我看到的除 AS-MLP 外将纯 MLP 做成 Backbone 用于下游任务的,例如检测和分割。其原始论文为 Cyclemlp: A mlp-like architecture for dense prediction,官方代码以及开源到了 Github。与 HireMLP 光说不做相比,明显 CycleMLP 更具贡献点。值得一提的是,AS-MLP 在 7.18 挂到 Arxiv,而 CycleMLP 是 7.21,晚了 3 天,所以大家都说自己是第一个用于下游任务的 Backbone 其实无可厚非。CycleMLP 也是通过将不同空间位置的特征对齐到同一个通道,然后使用通道方向的 $1 \times 1$ 卷积实现局部性能以及对图像尺寸不敏感。但是,细究 AS-MLP 和 CycleMLP 的特征图移动方式,他们的思想和做法还是基本一致的。CycleMLP 最终在 ImageNet1k 上取得了 83.2% 的性能,在 ADE20K 上取得了 45.1 mIoU(Swin 则分别是 83.3% 和 45.2 mIoU)。CycleMLP 与 SOTA 模型和其他 MLP 结构在 ImageNet 上的性能比较如下所示:
2. CycleMLP
这次讲解我还是先讲局部 CycleMLP Block 结构,再描述网络的整体结构。
2.1 CycleMLP Block
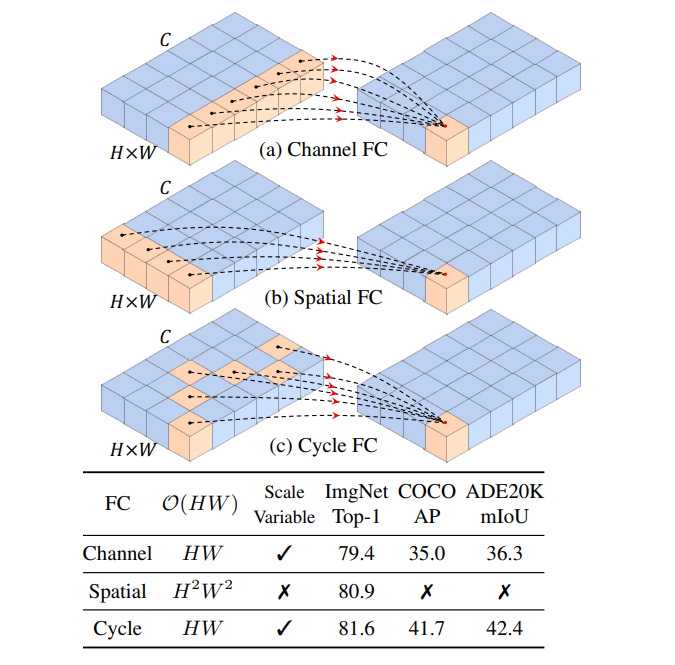
单个 CycleMLP Block 依然是分为 Token-mixing MLP 和 Channel mixing MLP,其中作者主要的贡献点在于替换 MLP-mixer 的 Token-mixing MLP 为 Cycle-FC。所以整个 CycleMLP Block 可以描述为: \(\begin{aligned} &Y=\text { Cycle-FC }(\operatorname{LN}(X))+X \\ &Z=\text { Channel-MLP }(\operatorname{LN}(Y))+Y \end{aligned}\) 何为 Cycle-FC ?要回答这个问题,我们首先来回顾一下 Channel FC 以及 Spatial FC.
Channel FC 即通道方向的映射,等效与 $1 \times 1$ 卷积,其参数量与图像尺寸无关,而与通道数(token 维度)有关。假设输入输出特征图尺寸一致,则参数量为 $C^2$,其中 $C$ 为通道数。而计算量则为 $HWC^2$,其中 $HW$ 分别为特征图的高和宽。如果只考虑计算量与图像尺寸的影响的话,则为 $O(HW)$。
Spatial FC 即 MLP-Mixer 使用的 Token-mixing 全连接层,在这里我们都是只考虑一个全连接层,则其实现的是 $HW -> HW$ 的映射,参数量为 $H^2W^2$,计算量也为 $H^2W^2C$,如果只考虑计算量与图像尺寸的影响的话,则为 $O(H^2W^2)$。并且 $HW$ 大小固定,网络对于不同图像分辨率的输入不可接受,且不能用于下游任务以及使用类似 EfficientNetV2 等的多分辨率训练策略。
为什么我们可以在复杂度分析时只考虑 $HW$ 的影响呢?因为在金字塔结构的 MLP 中,通常一开始的 patch size 为 4,然后输入尺寸为 $224 \times 224$,则一开始的 $H = W = 56 = 224 / 4$,而 $C = 64$ 或者 $96$,所以 $C \ll HW$。如果对于下游任务而言,例如输入变为了 $512 \times 512$,则它们之间的差距更大了。为此在这里我们可以在复杂度分析中暂时只考虑 $HW$ 而忽略 $C$。
为了同时克服 Spatial 对于图像输入尺寸敏感以及计算量大的问题,作者提出了 Cycle-FC。其只是用通道方向的映射并且计算量和 Channel FC 保持一致。其说白了就是不断地以 [+1 0 -1 0 +1 0 -1 0 +1 ….] 的方式移动特征图,将不同空间位置的特征对齐到同一个通道上,然后使用 $1 \times 1$ 卷积。
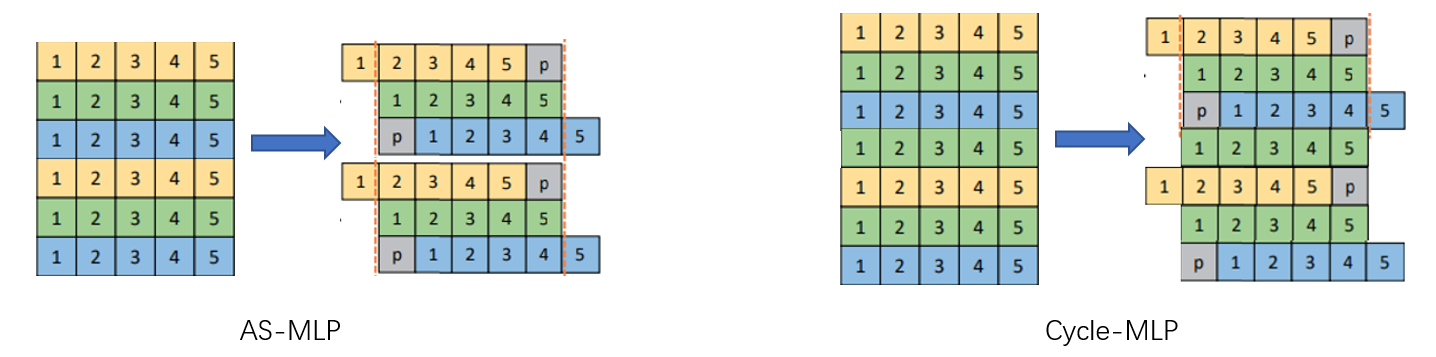
回忆 AS-MLP,其采用的特征图移动方式则为 [+1 0 -1 +1 0 -1 +1 0 -1] 这样的成组方式,CycleMLP 则是使用“楼梯型”方式,但是其思想没有本质不同。此外,AS-MLP 确实对特征图进行了 Shift,并且采用了 zero-padding,而 CycleMLP 在具体实现过程中则是使用可变形卷积加以实现的。我个人对于 AS-MLP 与 CycleMLP 的理解如下图所示,可见他们其实核心思想是一致的。
from torchvision.ops.deform_conv import deform_conv2d
CycleMLP 与 AS-MLP 只并行 H 和 W 方向的移动不同,CycleMLP 其实是三条支路并行:H 方向,W 方向,以及不移动特征图做通道方向映射。此外,AS-MLP 在一开始还做了一此 Channel Projection 进行降维。
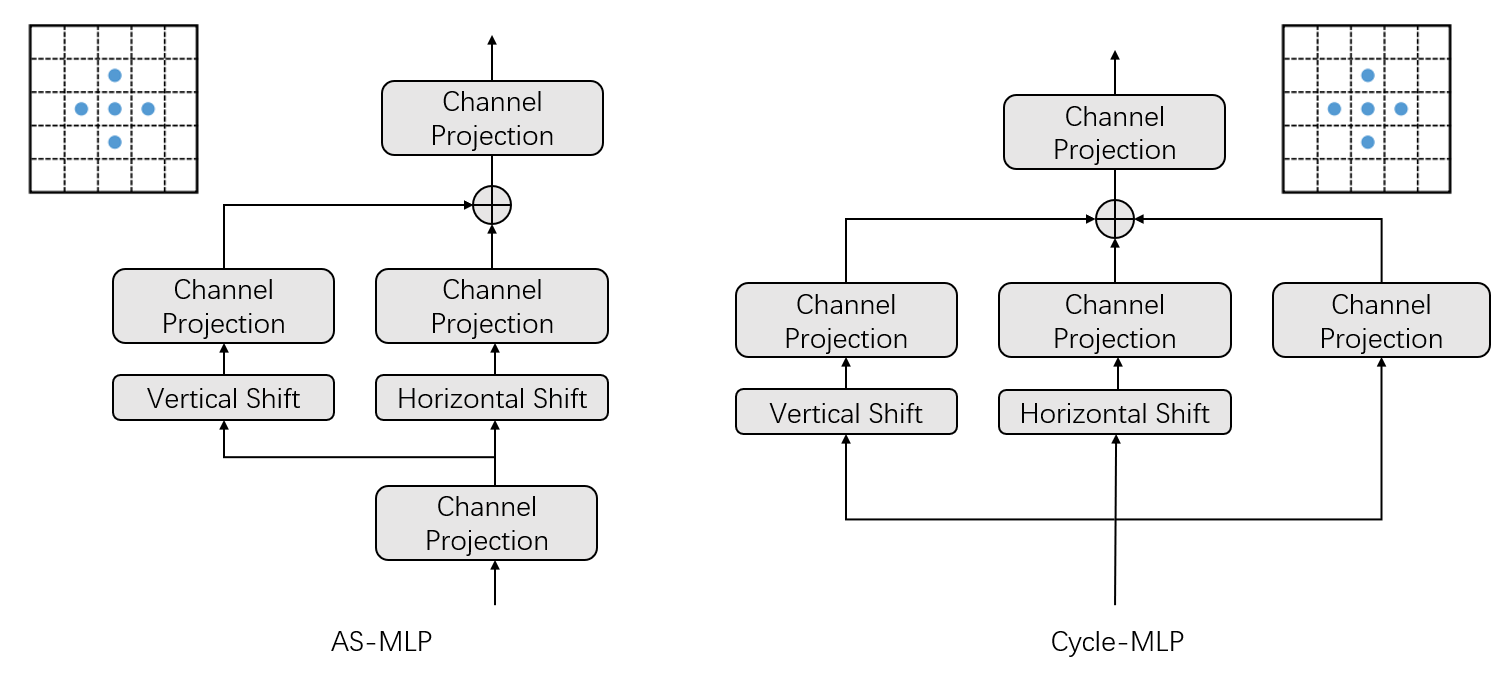
CycleMLP 最终使用的和 ViP 一样,使用 Split Attention 来融合三条支路。
class CycleMLP(nn.Module):
def __init__(self, dim, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
self.sfc_h = CycleFC(dim, dim, (1, 3), 1, 0)
self.sfc_w = CycleFC(dim, dim, (3, 1), 1, 0)
self.reweight = Mlp(dim, dim // 4, dim * 3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
h = self.sfc_h(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
w = self.sfc_w(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x
最后提一句,作者将投影区间定义为是 Pseudo-Kernel,这其实也是我们常说的 感受野 一词。
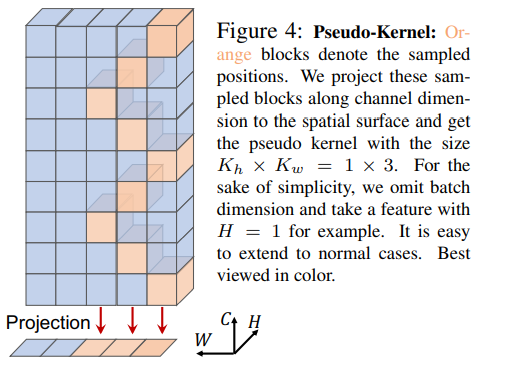
2.2 整体网络结构
CycleMLP 的 Patch Embedding 也很有特色,使用卷积核大小为 $7 \times 7$ ,步长为 4 的卷积。后续 Hire-MLP 其实也是这样进行的 Patch Embedding。相比而言 Swin 使用卷积核大小为 $4 \times 4$,步长为 4 的卷积。在近期的我自己的小实验中也发现:Patch Embedding 时具有重叠会更好,这样可以避免边界效应并在小数据集上提升性能。CycleMLP 中间采用多阶段金字塔模型,总共分为 4 个阶段,每个阶段交替重复使用 CycleMLP Block。下采样使用卷积核大小为 $3 \times 3$,步长为 2 的卷积,这样做也有重叠,Hire-MLP 也是这样子哈。最后经过全局池化后连接一个全连接分类器即可。作者一共提出来了四种配置:
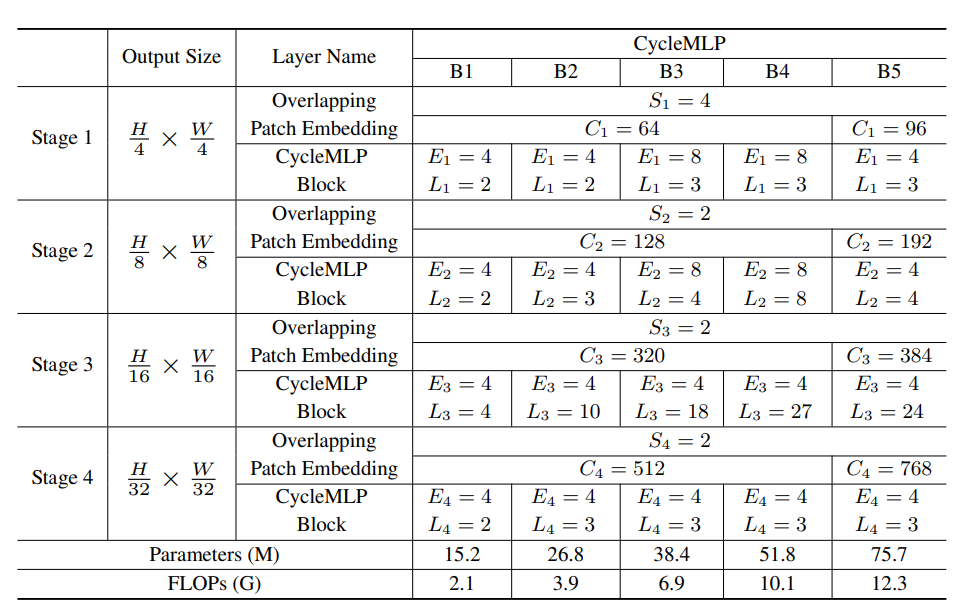
在这四种配置,$S_i$ 指 Patch Embedding 中的 Patch size,$C_i$ 指 Patch Embedding 的输出编码特征维度,$E_i$ 为 Channel-mixing MLP 中两个全连接层中第一个全连接层的 expand radio,$L_i$ 则是不同 Stage 中 Block 的重复次数。
3. 下游任务实验
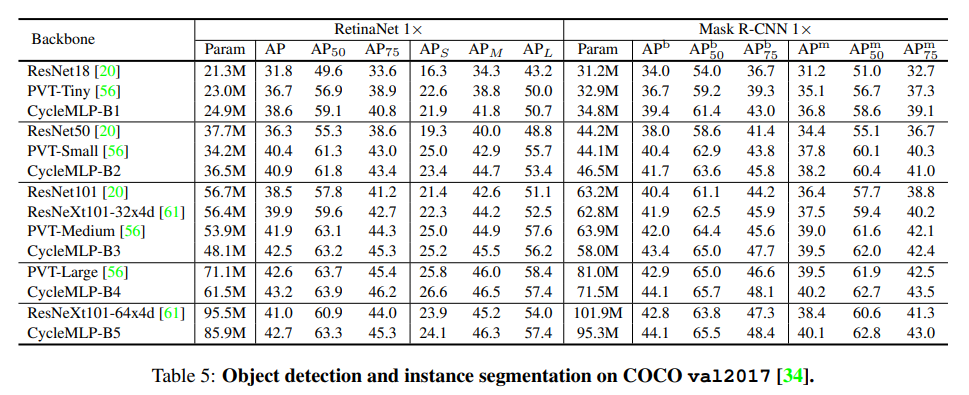
CycleMLP 旨在为 MLP 模型的目标检测、实例分割和语义分割提供一个有竞争力的基线。与 AS-MLP 不同之处在于,CycleMLP 在 ADE20K 上进行实验,而 AS-MLP 在 COCO 上进行的实验。这真的是巧合,还是故意避开?不敢问也不敢说。
目标检测性能表现:相比 PVT,CycleMLP 都更具有优势。
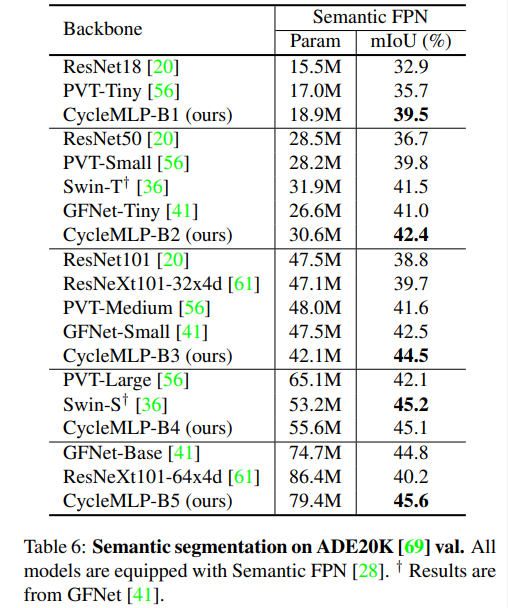
语义分割性能表现:特别是,CycleMLP 在 ADE20K val 上达到了 45.1 mIoU,与 Swin (45.2 mIOU) 相当。
4. 消融实验
作者一共进行了三组消融实验:
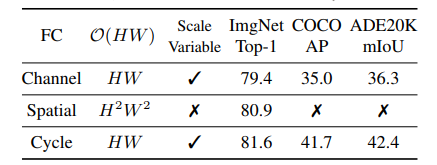
- Cycle-FC VS Spacial-FC and Channel-FC: 作者将 CycleMLP 中的 Cycle-FC 替换为 Spacial-FC 或者 Channel-FC,结果发现 CycleMLP 具有更好的性能。但是只有 Channel-FC,也能达到 79.4% 的性能,真的这么高吗,比 ResNet 高那么多…
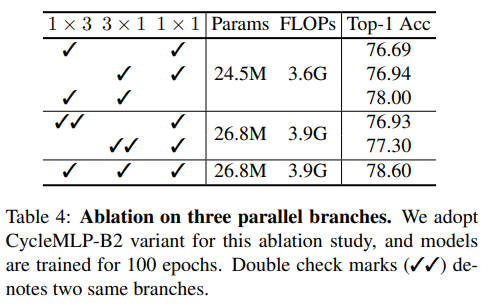
- Cycle-FC 中三条支路的选择:Cycle-FC 中作者并行了三条支路,对他们的消融实验发现,同时拥有正交 H 和 W 方向效果很好,加上不动之后效果更好。两倍 H 方向或者两倍 W 方向比仅含有 H 或者 W 方向会好一些。
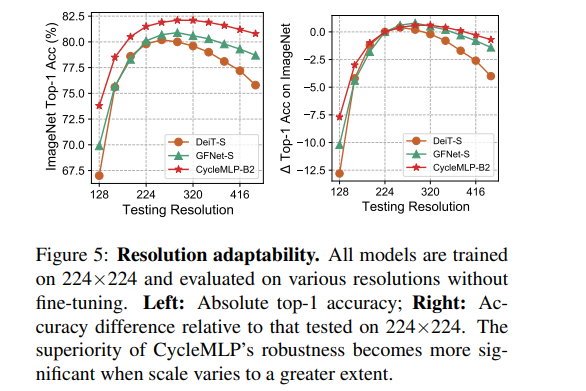
- 测试分辨率的影响:最终发现测试正确率随分辨率先升后降,CycleMLP 表现最好。
4. 总结与反思
CycleMLP 提出了 Cycle-FC,即将不同 token 的特征对齐到同一个通道,然后使用通道映射,从而实现网络参数量计算量的降低,以及对图像分辨率不敏感。CycleMLP 也在下游任务上测试了自己的性能表现。整体而言做得还是很充分的。不过其试图造一些新的名词以强化贡献,例如 Cycle-FC 其实就是移动特征图,Pseudo-Kernel 其实就是卷积核感受野的概念。最终 CycleMLP 通过三条并行的支路构建了十字形感受野。相比 AS-MLP,CycleMLP 在感受野分析上略显不足,没有更泛化地分析以及进行消融实验。比如 CycleMLP 也可以间隔采样,例如 [+4 +2 0 -2 -4 -2 0 2 4 2 0 -2 …..],就可以构建 AS-MLP 那种空洞的更大范围的感受野。(最后插一句:CycleMLP 和 AS-MLP,就像 ResMLP 与 MLP-Mixer,学术界的 Idea 真的能够这么惊人的一致吗?)
5. 代码
模型代码见 此处。
import os
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from timm.models.layers.helpers import to_2tuple
import math
from torch import Tensor
from torch.nn import init
from torch.nn.modules.utils import _pair
from torchvision.ops.deform_conv import deform_conv2d as deform_conv2d_tv
# https://github.com/ShoufaChen/CycleMLP/blob/main/cycle_mlp.py
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .96, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD, 'classifier': 'head',
**kwargs
}
default_cfgs = {
'cycle_S': _cfg(crop_pct=0.9),
'cycle_M': _cfg(crop_pct=0.9),
'cycle_L': _cfg(crop_pct=0.875),
}
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class CycleFC(nn.Module):
"""
"""
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size, # re-defined kernel_size, represent the spatial area of staircase FC
stride: int = 1,
padding: int = 0,
dilation: int = 1,
groups: int = 1,
bias: bool = True,
):
super(CycleFC, self).__init__()
if in_channels % groups != 0:
raise ValueError('in_channels must be divisible by groups')
if out_channels % groups != 0:
raise ValueError('out_channels must be divisible by groups')
if stride != 1:
raise ValueError('stride must be 1')
if padding != 0:
raise ValueError('padding must be 0')
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = _pair(stride)
self.padding = _pair(padding)
self.dilation = _pair(dilation)
self.groups = groups
self.weight = nn.Parameter(torch.empty(out_channels, in_channels // groups, 1, 1)) # kernel size == 1
if bias:
self.bias = nn.Parameter(torch.empty(out_channels))
else:
self.register_parameter('bias', None)
self.register_buffer('offset', self.gen_offset())
self.reset_parameters()
def reset_parameters(self) -> None:
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
def gen_offset(self):
"""
offset (Tensor[batch_size, 2 * offset_groups * kernel_height * kernel_width,
out_height, out_width]): offsets to be applied for each position in the
convolution kernel.
"""
offset = torch.empty(1, self.in_channels*2, 1, 1)
start_idx = (self.kernel_size[0] * self.kernel_size[1]) // 2
assert self.kernel_size[0] == 1 or self.kernel_size[1] == 1, self.kernel_size
for i in range(self.in_channels):
if self.kernel_size[0] == 1:
offset[0, 2 * i + 0, 0, 0] = 0
offset[0, 2 * i + 1, 0, 0] = (i + start_idx) % self.kernel_size[1] - (self.kernel_size[1] // 2)
else:
offset[0, 2 * i + 0, 0, 0] = (i + start_idx) % self.kernel_size[0] - (self.kernel_size[0] // 2)
offset[0, 2 * i + 1, 0, 0] = 0
return offset
def forward(self, input: Tensor) -> Tensor:
"""
Args:
input (Tensor[batch_size, in_channels, in_height, in_width]): input tensor
"""
B, C, H, W = input.size()
return deform_conv2d_tv(input, self.offset.expand(B, -1, H, W), self.weight, self.bias, stride=self.stride,
padding=self.padding, dilation=self.dilation)
def extra_repr(self) -> str:
s = self.__class__.__name__ + '('
s += '{in_channels}'
s += ', {out_channels}'
s += ', kernel_size={kernel_size}'
s += ', stride={stride}'
s += ', padding={padding}' if self.padding != (0, 0) else ''
s += ', dilation={dilation}' if self.dilation != (1, 1) else ''
s += ', groups={groups}' if self.groups != 1 else ''
s += ', bias=False' if self.bias is None else ''
s += ')'
return s.format(**self.__dict__)
class CycleMLP(nn.Module):
def __init__(self, dim, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
self.sfc_h = CycleFC(dim, dim, (1, 3), 1, 0)
self.sfc_w = CycleFC(dim, dim, (3, 1), 1, 0)
self.reweight = Mlp(dim, dim // 4, dim * 3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
h = self.sfc_h(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
w = self.sfc_w(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x
class CycleBlock(nn.Module):
def __init__(self, dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn=CycleMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam
return x
class PatchEmbedOverlapping(nn.Module):
""" 2D Image to Patch Embedding with overlapping
"""
def __init__(self, patch_size=16, stride=16, padding=0, in_chans=3, embed_dim=768, norm_layer=None, groups=1):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.patch_size = patch_size
# remove image_size in model init to support dynamic image size
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride, padding=padding, groups=groups)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
return x
class Downsample(nn.Module):
""" Downsample transition stage
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
assert patch_size == 2, patch_size
self.proj = nn.Conv2d(in_embed_dim, out_embed_dim, kernel_size=(3, 3), stride=(2, 2), padding=1)
def forward(self, x):
x = x.permute(0, 3, 1, 2)
x = self.proj(x) # B, C, H, W
x = x.permute(0, 2, 3, 1)
return x
def basic_blocks(dim, index, layers, mlp_ratio=3., qkv_bias=False, qk_scale=None, attn_drop=0.,
drop_path_rate=0., skip_lam=1.0, mlp_fn=CycleMLP, **kwargs):
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(CycleBlock(dim, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, drop_path=block_dpr, skip_lam=skip_lam, mlp_fn=mlp_fn))
blocks = nn.Sequential(*blocks)
return blocks
class CycleNet(nn.Module):
""" CycleMLP Network """
def __init__(self, layers, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dims=None, transitions=None, segment_dim=None, mlp_ratios=None, skip_lam=1.0,
qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm, mlp_fn=CycleMLP, fork_feat=False):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = PatchEmbedOverlapping(patch_size=7, stride=4, padding=2, in_chans=3, embed_dim=embed_dims[0])
network = []
for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers, mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop_rate, drop_path_rate=drop_path_rate,
norm_layer=norm_layer, skip_lam=skip_lam, mlp_fn=mlp_fn)
network.append(stage)
if i >= len(layers) - 1:
break
if transitions[i] or embed_dims[i] != embed_dims[i+1]:
patch_size = 2 if transitions[i] else 1
network.append(Downsample(embed_dims[i], embed_dims[i+1], patch_size))
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
# TODO: more elegant way
"""For RetinaNet, `start_level=1`. The first norm layer will not used.
cmd: `FORK_LAST3=1 python -m torch.distributed.launch ...`
"""
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
else:
# Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self.cls_init_weights)
def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, CycleFC):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def init_weights(self, pretrained=None):
""" mmseg or mmdet `init_weight` """
if isinstance(pretrained, str):
logger = get_root_logger()
load_checkpoint(self, pretrained, map_location='cpu', strict=False, logger=logger)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
x = self.patch_embed(x)
# B,C,H,W-> B,H,W,C
x = x.permute(0, 2, 3, 1)
return x
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out.permute(0, 3, 1, 2).contiguous())
if self.fork_feat:
return outs
B, H, W, C = x.shape
x = x.reshape(B, -1, C)
return x
def forward(self, x):
x = self.forward_embeddings(x)
# B, H, W, C -> B, N, C
x = self.forward_tokens(x)
if self.fork_feat:
return x
x = self.norm(x)
cls_out = self.head(x.mean(1))
return cls_out
@register_model
def CycleMLP_B1(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [2, 2, 4, 2]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_S']
return model
@register_model
def CycleMLP_B2(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [2, 3, 10, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_S']
return model
@register_model
def CycleMLP_B3(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [3, 4, 18, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_M']
return model
@register_model
def CycleMLP_B4(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [3, 8, 27, 3]
mlp_ratios = [8, 8, 4, 4]
embed_dims = [64, 128, 320, 512]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_L']
return model
@register_model
def CycleMLP_B5(pretrained=False, **kwargs):
transitions = [True, True, True, True]
layers = [3, 4, 24, 3]
mlp_ratios = [4, 4, 4, 4]
embed_dims = [96, 192, 384, 768]
model = CycleNet(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
mlp_ratios=mlp_ratios, mlp_fn=CycleMLP, **kwargs)
model.default_cfg = default_cfgs['cycle_L']
return model