深度学习之图像分类(二十八)Sparse-MLP(MoE) 网络详解
本工作向 Vision MLP 中引入 Mixture-of-Experts (MoE), 但是 发现其 MoE 使用方法和 Scaling Vision with Sparse Mixture of Experts 几乎一模一样,所以又是一篇在网络上的真实贡献“微乎其微”的工作…

1. 前言
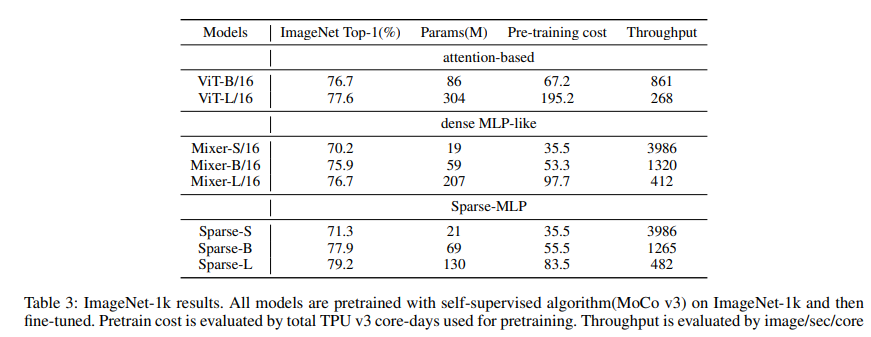
一个月前(2021.9.8),新加坡国立大学提出了 Sparse-MLP,将 Mixture-of-Experts(MoE) 引入 MLP,使用条件计算来实现再扩充参数的同时,还可以保证计算成本不会太高。并引入了放缩特征维度的结构 ($1 \times 1$ 卷积) 降低计算量。经过 MoCo v3 自监督预训练,最终在 ImageNet-1k 上达到了 79.2% 的 Top-1 精度,超过了 MLP-Mixer 2.5%。其论文为 Sparse-MLP: A Fully-MLP Architecture with Conditional Computation,代码暂时没有开源。
本文的核心在于将 MoE 引入 MLP,其实是完全参考2021.6月的工作 Scaling Vision with Sparse Mixture of Experts,损失函数也直接照抄。唯一的不同在于别人做 Transformer-based,所以多头注意力机制没有变动,将 MoE 引入了后面的全连接,即对应 MLP-based 的 Channel-mixing MLP。本工作则对于空间 MLP 和通道 MLP 都会使用 MoE 进行改造。所以本博客主要就是讲解一下这个是怎么实现的,关于背后的思想之后有空再学习一下”开山之祖“。最终网络在 ImageNet 上的性能对比结果如下所示:
后续部分参考描述见 此处。
2. Mixture of Experts
2.1 背景
MoE 的思想主要来自于 ICLR 2017 的一篇文章:Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,该文提到 “The capacity of a neural network to absorb information is limited by its number of parameters. Conditional computation, where parts of the network are active on a per-example basis, has been proposed in theory as a way of dramatically increasing model capacity without a proportional increase in computation.”。这篇文章通过在 LSTM 中间插入多个专家结构,通过可训练的门控网络来对专家们进行 稀疏组合,从而将模型的能力(capacity)提升了超过 1000 倍并且只有少量的效率损失。除了主要的想法与这篇文章类似外,针对 MoE 结构的优化策略也基本一脉相承。
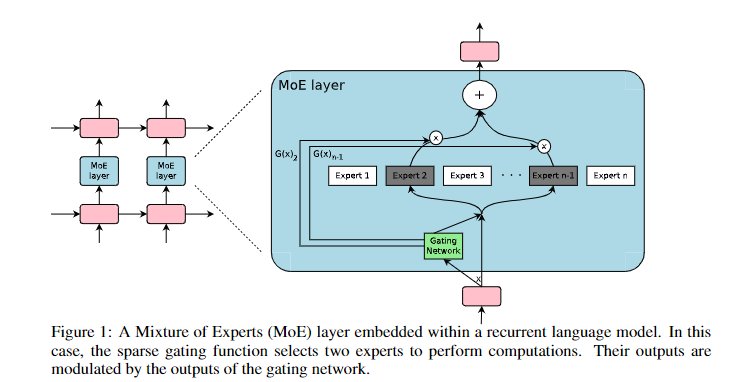
相同的研究团队在前一天(2021.9.7)在 arxiv 上挂了另外一篇文章 Go Wider Instead of Deeper,其实是一样的,不过是只将 MoE 放到了 FFN,即通道 MLP 中。
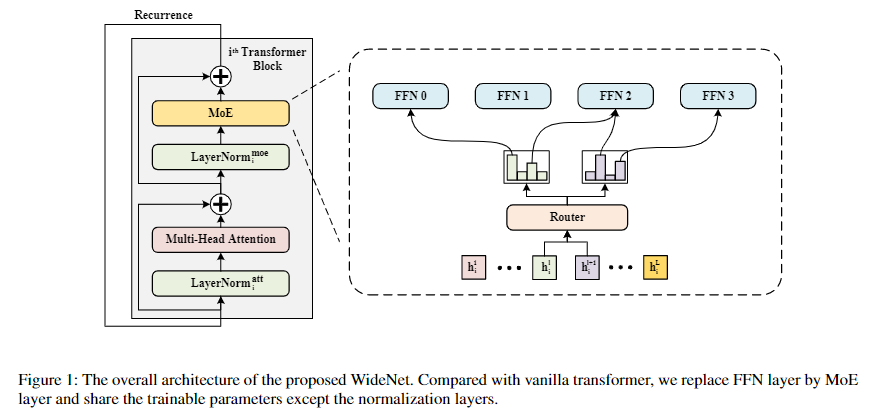
但是该团队的两篇工作其实都是”借鉴“谷歌团队(2021年6月)发布的 Scaling Vision with Sparse Mixture of Experts。粗略看了这个工作后,一下子觉得这个团队的近两个工作的贡献度直线下滑,甚至跌入谷底…
2.2 MoE
专家混合操作的核心在于: \(\operatorname{MoE}(x)=\sum_{i=1}^{N} G(x)_{i} E_{i}(x), \\ G(x)=\operatorname{TopK}\left(\operatorname{softmax}\left(W_{g}(x)+\epsilon\right)\right): \mathbb{R}^{D} \rightarrow \mathbb{R}^{N}, \\ E_{i}(x): \mathbb{R}^{D} \rightarrow \mathbb{R}^{D}\) 此处第一行公式是包含 $N$ 个专家的 MoE 层的聚合操作,用于计算以输入为条件的路由权重的门控网络 G(使用 Softmax 生成归一化权重,这里引入了噪声 $\epsilon \sim \mathcal{N}\left(0, \frac{1}{N^{2}}\right)$ 从而探索更好的分配策略),以及第 $i$ 个专家层映射。
可见其核心就是对输入 $x$ 进行等维映射,这种等维映射可以有 $N$ 种。然后另一条支路对 $x$ 进行门控计算,权重 $W_g \in \mathbb{R}^{D \times N}$ 表示 MoE 层的门控权重矩阵(gating weight matrix),其将输入的 $D$ 维的 $x$ 的映射到专家数量 $N$,由 Softmax 处理后即获得每个样本 $x$ 被分配到各个专家的权重。经过 Softmax 之后取前 $K$ ($K$ 通常取 1 或者 2)的权重,最终输出即得分前 $K$ 个专家的加权和。
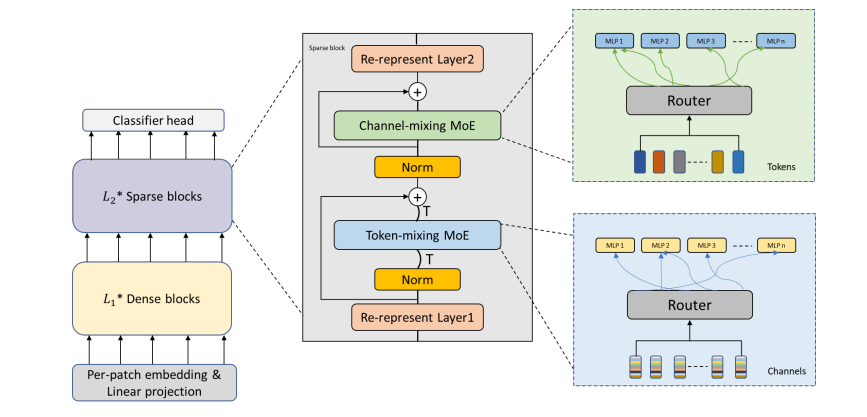
本文主要将 Mixer-MLP 中的最后几层空间和通道 MLP 进行了替换,替换成了 MoE 结构(包含空间和通道两种结构)。这样的设定有助于引入更多的参数,提升模型的能力。这与谷歌团队工作将 ViT 的后几个 block 添加 MoE 是一样的思路。结果可见,加到后面确实会好一些。
2.3 损失函数
多专家模型的训练是不容易的。主要是由于稀疏的门控路由机制导致并不是所有的专家必然可以被得到充分的训练,也就是所谓的负载不均衡问题。所以使用多专家设定的方法大多数都需要特殊的损失来进行针对性的处理。对于损失函数,本文延续了之前工作的设定,应用了负载均衡损失(Load Balance Loss)。该损失鼓励横跨专家对输入进行均衡分配。
该损失包含两部分设定:Importance loss and Load loss
- 重要性损失(Importance Loss):目的是让各个专家信息传播过程中的重要性尽量相近,这样可以保证各个专家可以被尽量选择到并被充分的训练。
- 首先引入重要性的定义:$\operatorname{Imp}(X)=\left{\sum_{x \in X} \operatorname{softmax}\left(W_{g} x\right){i}\right}{i=1}^{N}$,第 $i$ 个专家的重要性即所有第 $i$ 个 Softmax 的分数和;
- 权重 $W_g \in \mathbb{R}^{D \times N}$ 表示 MoE 层的门控权重矩阵(gating weight matrix),其将输入的 $D$ 维的 $x$ 的映射到专家数量 $N$,由 Softmax 处理后即获得每个样本 $x$ 被分配到各个专家的权重。这里将与第 $i$ 个专家有关的各个输入对应的权重加和后获得其对于 batch 输入 $X$ 的重要性度量。这可以反映出各个专家相较于其他专家,在整体输入被分配处理的过程中所起到的相对作用。
- 为了尽可能均衡各个专家的重要性,使大家都能更好的“表现”,所以各个专家的重要性应该尽量均衡。于是使用重要性的平方变异系数(the squared coefficient of variation of the importance distribution over experts)作为重要性损失。从公式可见,损失最小要求方差小,且均值大。即保证所有专家平均而言具有相似的路由权重,权重又不至于大家都很小。
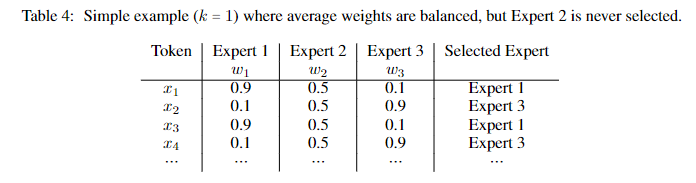
论文 Scaling Vision with Sparse Mixture of Experts 的表 4 能帮我们更好地理解专家选择这一过程。
-
负载损失(Load Loss):重要性损失旨在保证所有专家平均而言具有相似的路由权重。但是不幸的是,不难想到这些看上去有着总体趋于平衡的权重的路由配置,仍然有一小部分专家获得了所有分配(可见上表,虽然输入1~4对专家的权重之和均为2,但是却在最终额选择中,仅仅只会选择到专家 1 和3,而 2 则无法得到合适的学习)。
-
为此这里引入了关于专家负载的定义:$\operatorname{Load}(X)=\left{\sum_{x \in X} p_{i}(x)\right}_{i=1}^{N}$
-
$p_{i}(x):=\operatorname{Pr}\left(G(x){i}>=\operatorname{threshold}{k}(G(x))\right)$ 表示专家 $i$ 在输入 batch 数据时,对各个样本而言被选中(门控路由大于阈值,即位于前 $k$ 个最大权重的专家中) 的概率和。这个概率看上去不太好搞定,但是作者们这里引入了一个正态分布的噪声,使得一切都可以计算了,大致如下式,最后是一个正态分布变量的概率的计算。
- \[\begin{aligned} & p_{i}(x):=\operatorname{Pr}\left(G(x)_{i}>=\text { threshold }_{k}(G(x))\right) \\ =& \operatorname{Pr}\left(W_{g}(x)_{i}+\epsilon>=\text { threshold }_{k}\left(W_{g}(x)+\epsilon\right)\right) \\ =& \operatorname{Pr}\left(\epsilon>=\operatorname{threshold}_{k}\left(W_{g}(x)+\epsilon\right)-W_{g}(x)_{i}\right) \end{aligned}\]
- 负载损失则表示为负载分布的平方变异系数:
所以 MoE 层损失为: $L_{a u x}=\lambda\left(\frac{1}{2} L_{i m p}+\frac{1}{2} L_{\text {load }}\right)$。这里的超参数 $\lambda$ 用来控制辅助损失在鼓励跨专家路由的平衡,也保证不会压制(overwhelm)原始的模型损失。实际与之前的工作设置一样,都设为 0.01。按照之前的工作,这个参数对于性能的影响不太明显。
-
2.4 Re-represent Layers
除了多专家层本身的设定,考虑到在原始的 MLP-Mixer 中,基于 patch 的 token 处理方式导致空间 token 数量小于通道数量的 1/3。这对于 MOEs,也就是空间层面上的 MoE 层而言,会导致路由部分与专家部分计算成本的不均衡。由于原始空间 token 数量和通道数量差异较大,这会导致在路由和专家前向计算时不平衡的计算成本(computational cost),所以作者们在空间 MoE 层的前后通过对空间 token 数量和通道数量进行平衡(使用 $1 \times 1$ 卷积进行重新线性投影),从而保证了更加平衡和有效的计算过程。
最终 Re-represent Layers 伪代码如下,实际中设置 $S_1 = 2S, C_1 = C / 2$:

可见,这里包含两层,一个用于输出,一个用于输入。二者搭配,用于平衡二者中间包裹的 MOEs 的运算(降低 MOEs 运算时的通道数量并增加空间 patch 数量。
可以看到,使用重表征层后虽然速度提升了,但是性能却没有下降,反而提升了。这是个有趣的现象。但是作者没有给出合理的解释和分析。仅仅是提了下其对于平衡路由和专家的计算成本的作用。那这样的结构直接用于 MLP-Mixer 中是否也会有提升?

3. 消融实验
论文的消融实验主要讨论了以下四点:
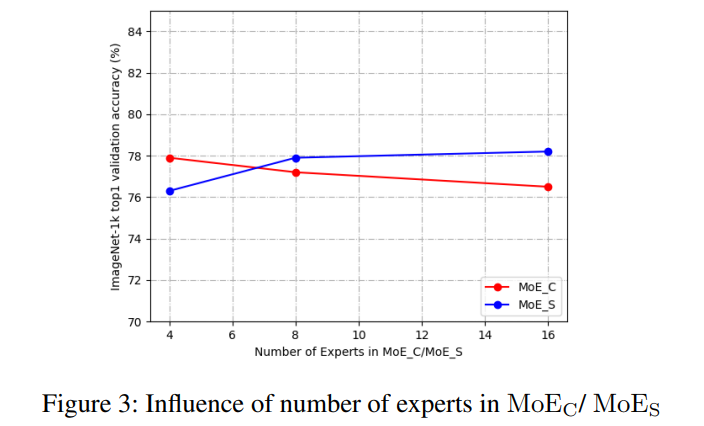
- 专家数量的影响:这里是分别固定 MoEs 和 MoEc 来做实验的,可以看到,MoEs 的增加可以带来性能的提升。但是 MoEc 却会导致下降,作者们认为是造成了过拟合(关于增加针对通道特征的专家数量会导致过拟合的现象在作者们之前的工作Go Wider Instead of Deeper中也有体现)。
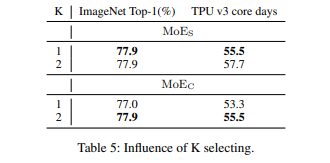
- 路由选择的专家的数量 $K$:这里针对不同的位置分别尝试了不同的 $K$ 值,这里都是基于 MLP-Mixer B 结构进行的实验。可以看到,对于通道专家需要同时应用更多,而空间单个即可。
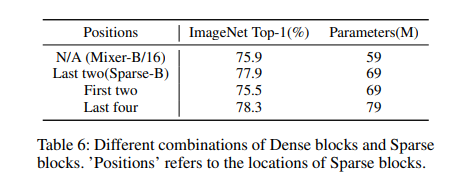
- Sparse Blocks 的位置,即 MoE 结构的位置 (已经在前面看过结果了)
- 重表征层的作用 (已经在前面看过结果了)
4. 反思与总结
本文核心贡献点一般,提出的 Sparse-MLP 其实依然对于图像尺寸敏感,也是使用全局感受野,仅仅是将 MoE 思想引入了其中。但是在谷歌工作之后做的,连续两天相同团队上传的论文,内容和谷歌的团队基本一致…
且不说工作是谁做出来的,将 MoE 思想引入 Transformer-based 和 MLP-based 还是非常有意思的。期待能将更多 CNN 中有意义的框架引入 Transformer-based 和 MLP-based 看看 ”组合“ 和 ”拼装“ 的进步。