深度学习之图像分类(二十六)ConvMixer网络详解
本次学习继 CNN –> Transformer –> MLP 架构之后,探讨究竟是 Transformer 和 MLP 对于 CNN 的改动优势在于后续 Block 还是 patch 切分和 Patch Embedding?或许这篇工作能够给予我们答案。

1. 前言
ConvMixer 目前正投稿于 ICLR2022,论文暂时在双盲审阶段,但是作者已经将论文当到了公开评审网站,其论文为 Patches Are All You Need?,代码也放到了 Github。近年来,在计算机视觉任务中,卷积神经网络一直占据主要地位。但最近,基于 Transformer 模型的架构,例如 ViT(Vision Transformer)架构,在许多任务中都表现出了引人注目的性能,它们通常优于经典卷积网络,尤其是在大型数据集上表现更佳。再到后来,具有更大自由度的 MLP 架构表示在大型数据集上也能工作很好。这看似带来了神经网络“表达范式”级别的改变。
Transformer 在 NLP 领域非常成功,迁移到视觉领域只是时间问题。然而,为了将 Transformer 应用于图像领域,如何将图像视作 token 是最先需要解决的问题。最简单的就是每个像素就是一个 token,但是这至少在目前并不可行。因为如果在每像素级别上应用 Transformer 中的自注意力层,它的计算成本将与每张图像的像素数成二次方扩展,现在的计算能力 hold 不住。所以折衷的方法是首先将图像分成多个 patch,再将这些 patch 线性嵌入,最后将 transformer 直接应用于 patch 集合,则计算成本是 patch 个数的二次方。在此思想基础上,MLP 架构也是这样操作进行的。
很自然有一个疑惑是:ViT 架构带来的强大性能是源自 Transformer 的自注意力机制,还是某种程度上是由于使用 patch 作为输入表示实现的呢?现在的 Patch Embedding 与传统的 stride = 1 的卷积不同,它直接将一个 $p \times p$ 的 patch 转换为 $c$ 维的向量,并不再在 patch 内为每一个位置保存那个位置的特征。
为了回答这个问题,本文作者希望提供一些证据(While these results are naturally just a snapshot):具体而言,本文提出了 ConvMixer,这是一个概念和实现都超级简单的模型,在思想上与 ViT 和 MLP-Mixer 相似,这些模型直接将 patch 作为输入进行操作,然后采用分离空间和通道维度的混合,并在整个网络中保持相同的大小和分辨率。然而,相比之下,该研究提出的 ConvMixer 仅使用标准卷积来实现混合步骤,空间方向使用单通道的组卷积,在通道维度上使用 $1 \times 1$ 卷积。尽管它非常简单,但实验表明,除了优于 ResNet 等经典视觉模型之外,ConvMixer 在类似的参数计数和数据集大小方面也优于 ViT、MLP-Mixer 及其一些变体。
2. A Simple Model: ConvMixer
2.1 Patch Embedding
本文主要想说明,近一年多来 CV 领域神经网络的改进的一大进步是 Patch Embedding。即 patches work well in convolutional architectures。常用的 Patch Embedding 其实就是一个 kernel size = patch size,stride = patch size 的卷积,然后经过一个激活函数和归一化层: \(z_0 = \mathrm{BN}\left(\sigma\left\{\operatorname{Conv}_{c_{\text{in} \rightarrow h}}(X, \text { stride }=p, \text { kernel size }=p) \right\}\right)\) 例如一个 $224 \times 224 \times 3$ 的自然图像作为输入,切分的 patch size = 7,嵌入维度为 1536。如果在 MLP-Mixer 或者 ViT 中,其表达的含义是将 $224 \times 224 \times 3$ 拆分为 $32 \times 32$ 个 patch,每个 patch 大小为 $7 \times 7 \times 3$。然后将其进行展平成为一个 $147$ 维度的向量。经过一个线性层变为一个 1536 维度的向量。这其实就是等价于使用 1536 个 $7 \times 7 \times 3$ 的卷积核对自然图像进行卷积,且 stride = 7,padding = 0。这就将每个 patch 变为 1536 个特征值。
2.2 ConvMixer Layer
在 ConvMixer Layer 中,作者采用分离空间和通道维度的混合,即先通过一个 Depthwise Conv(即组数等于通道数的分组卷积),再通过一个 Pointwise Conv(即 $1 \times 1$ 卷积)。每个卷积之后是一个激活函数和激活后的 BatchNorm:
\(\begin{aligned}
z_{l}^{\prime} &=\mathrm{BN}\left(\sigma\left\{\text { ConvDepthwise }\left(z_{l-1}\right)\right\}\right)+z_{l-1} \\
z_{l+1} &=\mathrm{BN}\left(\sigma\left\{\text { ConvPointwise }\left(z_{l}^{\prime}\right)\right\}\right)
\end{aligned}\)
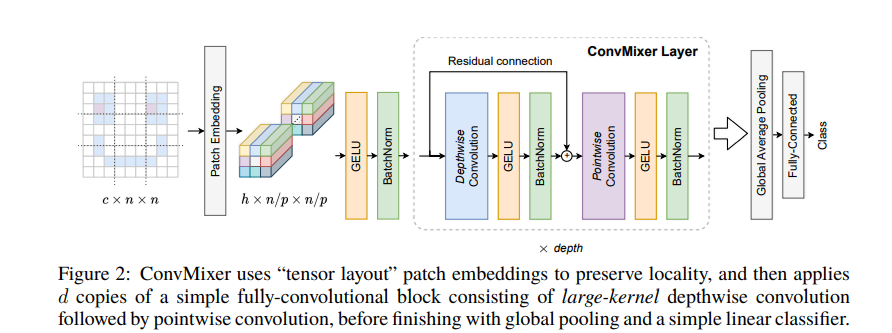
作者经过实验发现,在 ConvMixer Layer 的 Depthwise Conv 中使用平时不常用的大卷积核效果会好一些,因为先前工作的一个关键思想是 MLP 和自注意力可以混合较远的空间位置,即它们可以具有任意大的感受野。值得注意的是:如果卷积核大小和 patch 个数一致,并且每个组之间共享卷积核权重,则 ConvMixer 就变为了 MLPMixer。然而近期的工作如 AS-MLP,S2MLPv2 等则回归到图像的局部性。ConvMixer 的感受野范围比 AS-MLP,S2MLPv2 等大,但是它的性能却没有后者好。整体而言,ConvMixer 是把握中等范围的依赖。所以说真的是 patch 级别的大感受野好还是小感受野好,还是先大后小,先小后大好还不可知。
2.3 ConvMixer 网络结构
在 Patch Embedding 和多个 ConvMixer Layer 之后,经过一个全局池化,展平,全连接层即可获得分类输出,这与 ResNet 等 CNN、Swin、AS-MLP 等金字塔结构的分类头是一致的。
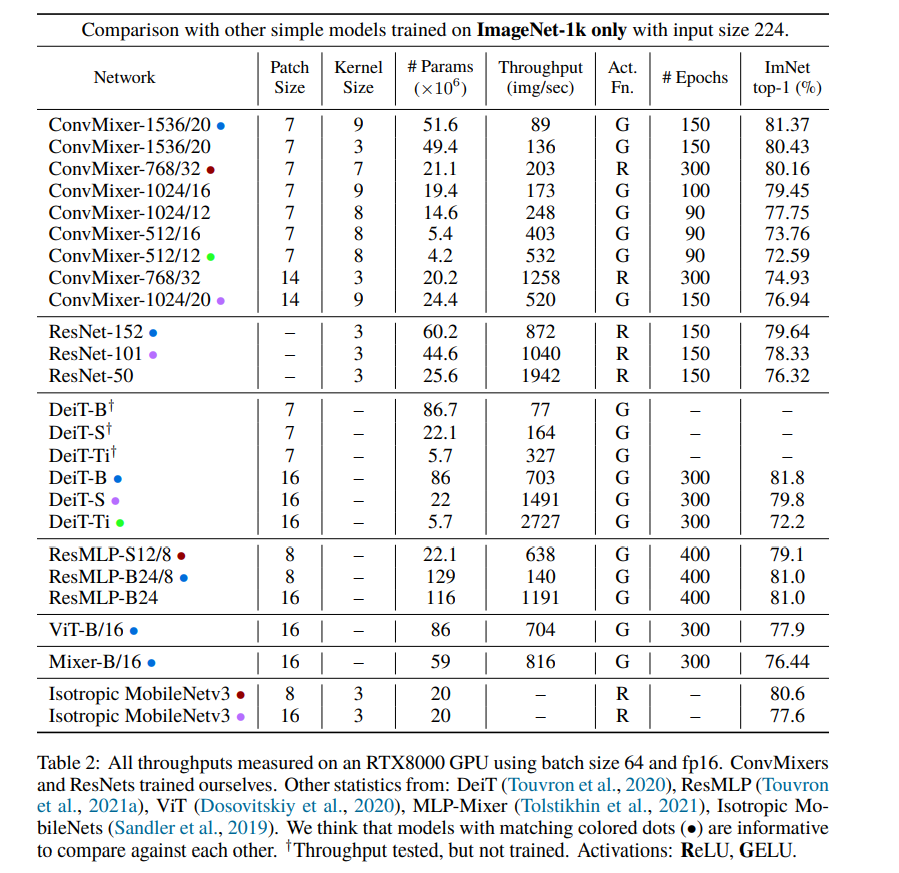
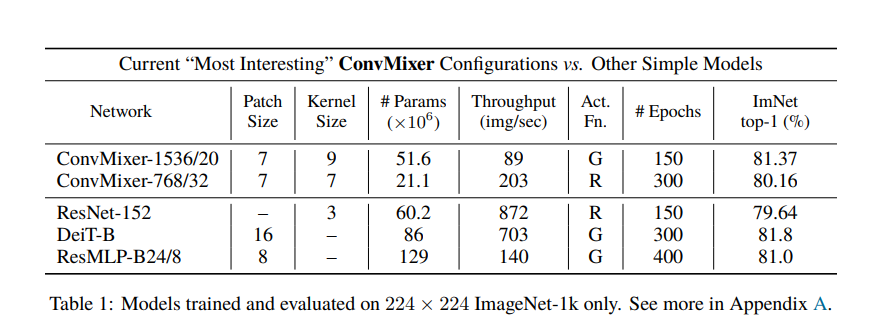
作者给出了一宽一深两个配置,Patch size 值最初切分的 patch 大小;kernel size 指 ConvMixer Layer 中 Depthwise Conv 使用的卷积核大小;Act. Fn 指激活函数 (GELU/ReLU)。1536/20 指的是 token 的维度为 1536,ConvMixer Layer 重复的次数为 20。
这里 GELU 和 RELU 都有,作者说到:他们使用 ReLU 训练了一个模型,以证明 GELU 是不必要的。
此外,因为使用的是卷积,作者发现 BN 比 LN 会略好一点点。
最后,ConvMixer 的推理速度较金字塔模型慢得多,这可能因为它们的 patch 更小,而 ConvMixer 是保大小不变的。(但是实际上 ConvMixer 对图像尺寸不敏感,所以也是可以变成金字塔结构的,不过效果怎么样不得而知)。
2.4 实现代码:
非官发复现的 pytorch 以及 Jittor 代码详见 此处。下面展示官方实现的代码:
import torch.nn as nn
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x):
return self.fn(x) + x
def ConvMixer(dim, depth, kernel_size=9, patch_size=7, n_classes=1000):
return nn.Sequential(
nn.Conv2d(3, dim, kernel_size=patch_size, stride=patch_size),
nn.GELU(),
nn.BatchNorm2d(dim),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(dim, dim, kernel_size, groups=dim, padding="same"),
nn.GELU(),
nn.BatchNorm2d(dim)
)),
nn.Conv2d(dim, dim, kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
) for i in range(depth)],
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(dim, n_classes)
)
3. Weight Visualizations
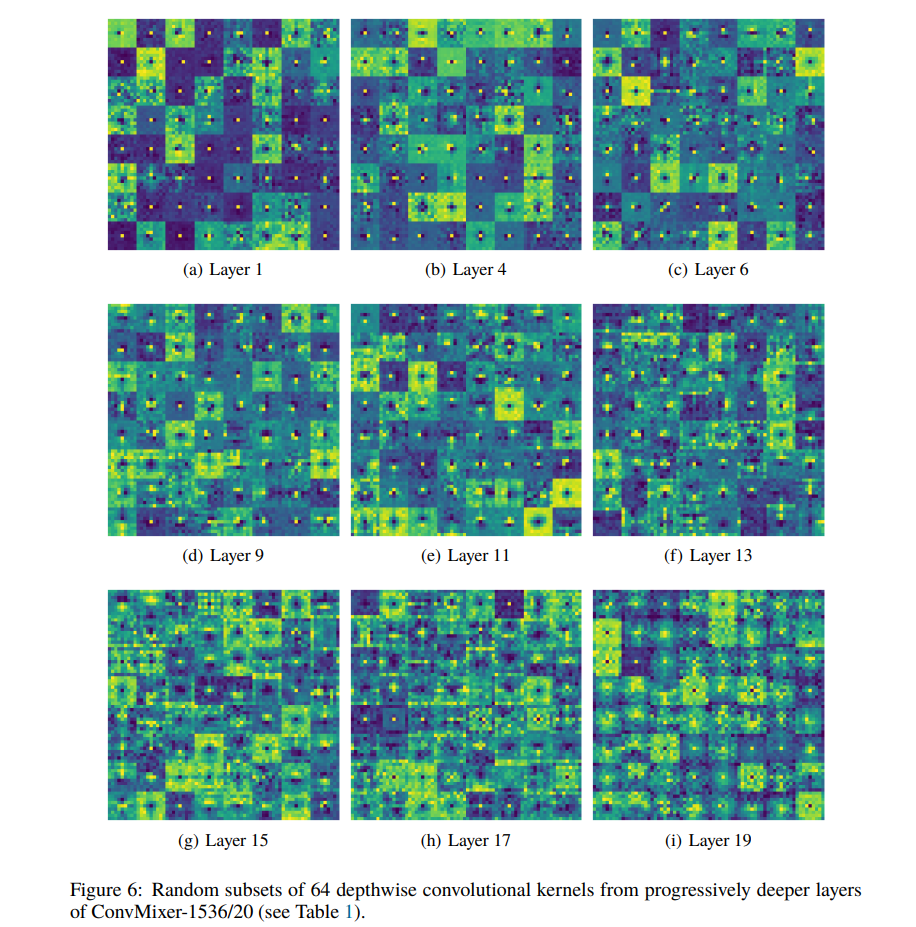
作者给出了学习之后 Patch Embedding 和 Depthwise Conv 的卷积核参数可视化,这也是我觉得非常有趣的地方。
首先看看 Patch Embedding 的卷积核参数 $14 \times 14 \times 3$,里面有很多黑白的很像 Gobar-like Kernel,其功能是“梯度计算”,说明卷积核在关注纹理;也有很多彩色的,说明卷积核在关注颜色差异。这其实和原始的 CNN 学习的东西很接近。 $7 \times 7 \times 3$ 的 卷积核也在学习纹理和颜色。从卷积的角度看,这些纹理和颜色其实是 patch 中心的,当 stride = 1 的话就是获得每个像素点的纹理特征和颜色特征。所以 patch embedding 我的理解则是将 patch 的纹理颜色特征给浓缩起来,然后可以学多种类型;以前的 stride = 1 的卷积则是记录每个像素点的颜色纹理信息,但是种类不是那么繁多。

其次我们看看 Depthwise Conv 的卷积核参数 $9 \times 9$ 可视化,让我觉得有趣的点在于在前期的卷积核参数中中间点为正值,其余位置为负值;在后期则半边正半边负,或者中间一圈正,外面一圈负。如果给出了特征图和权重一起分析,则可能会更好。
4. 反思与总结
先来看看大哥们怎么说:
特斯拉 AI 高级总监 Andrej Karpathy 讲:我被新的 ConvMixer 架构震撼了。
也有研究人员说:这项研究具有很重要的理论意义,因为它挑战了 ViT 有效性的原因。

还有网友表示:作为消融实验,我认为很有趣。我不认为这篇论文的目的是表达『 ConvMixer 是一个好的架构,值得研究者使用』,而是『这个简单的架构有效的帮助我们缩小了其他模型最有价值的特性范围』。
这篇文章其实只有四页出头,实验和实验配置都在附录。这也是我非常喜欢的地方。

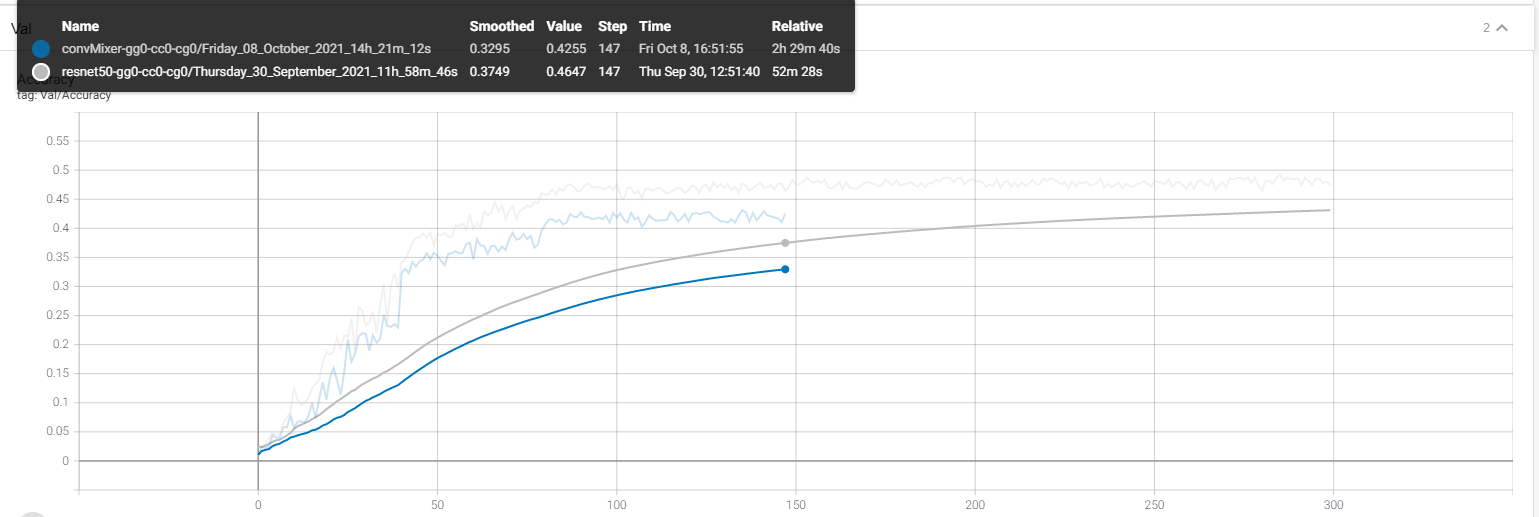
我非常赞同说本文的核心在于提出这个观点和论据,四页的篇幅已经足够了,让人们关注到 patch 切分和以前的 CNN 是不同的,并非建议说『 ConvMixer 是一个好的架构,值得研究者使用』。具体的实验结果是什么留给感兴趣的人看看附录。作者说他在 cifar10 很牛,但是我小小的跑了一下 Oxford 102 Flowers Dataset,不使用 ImageNet 预训练参数,验证集上 ConvMixer 差 ResNet50 还是有点点多的……