深度学习之图像分类(十九)Bottleneck Transformer(BoTNet)网络详解
上节有讲 ViT 结构。本节学习 CNN 与 Attention 的融合网络 BoTNet,即 Bottleneck Transformer。

1. 前言
BoTNet 为 UC Berkeley 和 谷歌团队合作发布在 2021 CVPR 的文章,Transformer 的一作 Ashish Vaswani 也在本文作者当中。BoTNet 原始论文为 Bottleneck Transformers for Visual Recognition。我们首先看一下 CV 领域 Self-Attention Model 分类,可分为纯 Attention Model 包括 ViT,此外则是 CNN + Attention。为什么要把 CNN 与 Attention 进行融合呢?其中一大原因就是因为纯 ViT 类型的结构对于输入尺寸特别敏感,不能变动,是 $224 \times 224$ 就是 $224 \times 224$ 。然而我们的目标检测,实例分割等任务的输入可能是 $1024 \times 1024$ 的大图。如果硬Train一发纯 Transformer,计算量怕你吃不消。与 CNN 融合的 Attention 结构也可分为 Transform 形式的,也可分为 Non-Local 形式的。 关于 NL 的知识可以参考知乎解答 Non-local neural networks,其实 NL 提到说 Self-Attention 是 NL 的一个特例,在 Non-Local 中没有位置编码 Position Embedding。CNN 融合的 Attention 可以放在 Backbone 外,将 CNN 的输出特征图进行映射后接入 Transformer,也可以直接将 Transformer block 嵌入 CNN Backbone 的单个 block 内。本次讲解的 BoTNet 则是将 Attention 模块融入到 CNN 原有的 block 中。
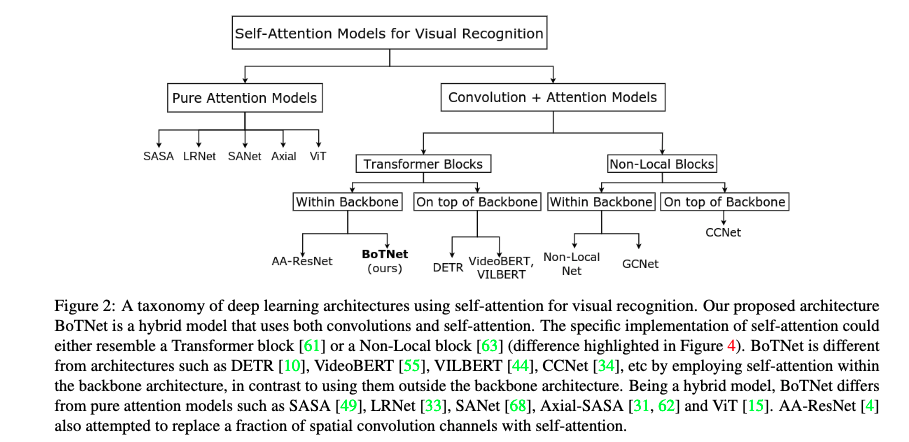
说难也难,说简单也简单,BoTNet 其实就是把 ResNet50 等使用的 Bottleneck 中间的 $3 \times 3$ 卷积给替换成了 Multi-Head Self-Attention,文中缩写为 MHSA。至于为什么要做这种替换,在哪里进行替换,是全体换呢还是像之前的 EfficientnetV2 一样对 MBConv 进行部分替换呢?这是本文之后要继续探讨的点。
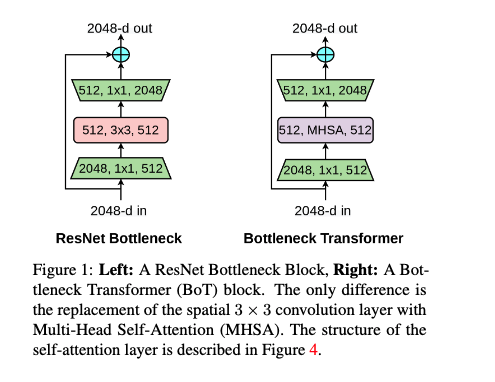
ResNet50 变成 BoTNet 之后能做什么?很自然,ResNet50 能做的 BoTNet 都能做。直接作为分类模型进行 ImageNet 分类,作为 Backbone 嵌入 Faster R-CNN 做目标检测,作为 Backbone 嵌入 Mask R-CNN 做实例分割。
2. Multi-Head Self-Attention
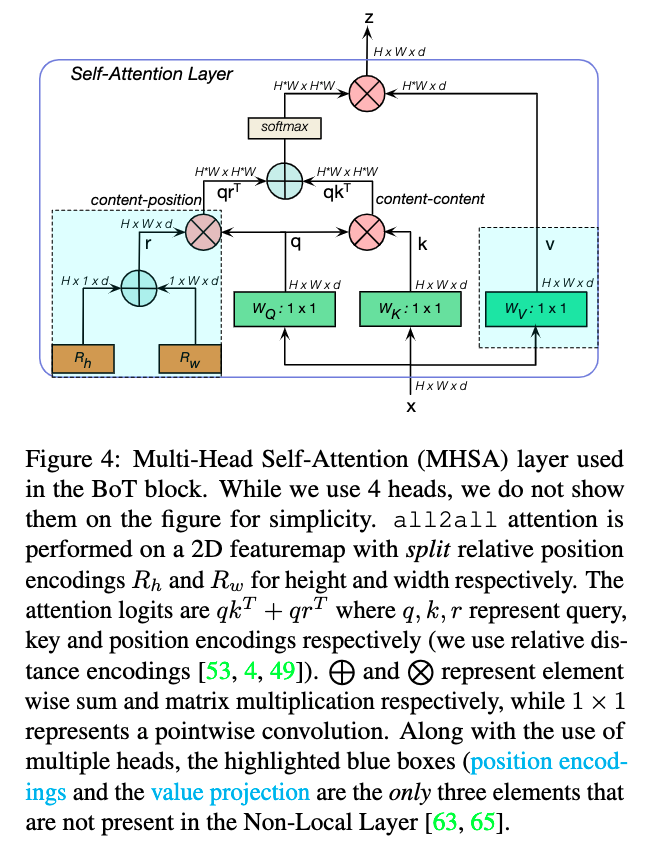
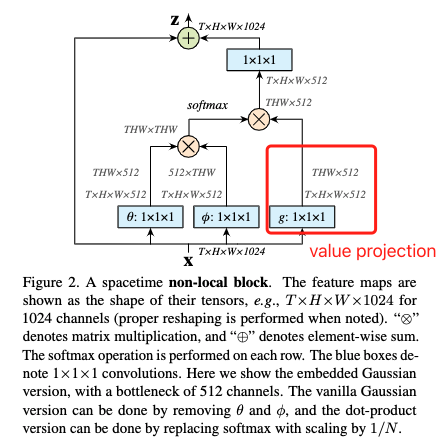
首先我们来看一下作者使用的 Multi-Head Self-Attention 结构。Bottleneck Transformer 中使用的 MHSA 结构如下所示。在实验中,作者使用的是 head = 4,在下图中并没有进行展示。MHSA 的输入尺寸为 $H \times W \times d$,分别表示输入特征矩阵的高宽以及单个 token 的维度(特征图的通道转换到最后一维来就行了), token 的数量即为 $H \times W$。此处的 relative position encodings 是我一直没有搞清楚的点。首先是初始化两个可学习的参数向量 $R_h$ 和 $R_w$,分别表示高度和宽度不同位置的位置编码,然后将它们通过广播机制加起来,那就是 $(i, j)$ 位置的编码为 $R_{h_i} + R_{w_j}$ 的两个 $d$ 维向量相加。这样做将 $H \times W \times d$ 个编码简化到了 $(H + W) \times d$。但是为什么这么来做呢,参考文献 [53, 4, 49] 是这么做的。此外,位置编码也不是直接加到输入上,而是与 query 矩阵进行矩阵乘法得到 Attention 的一部分,将其与 query 和 key 算出来的加和后经过 softmax 得到最终的 Attention。
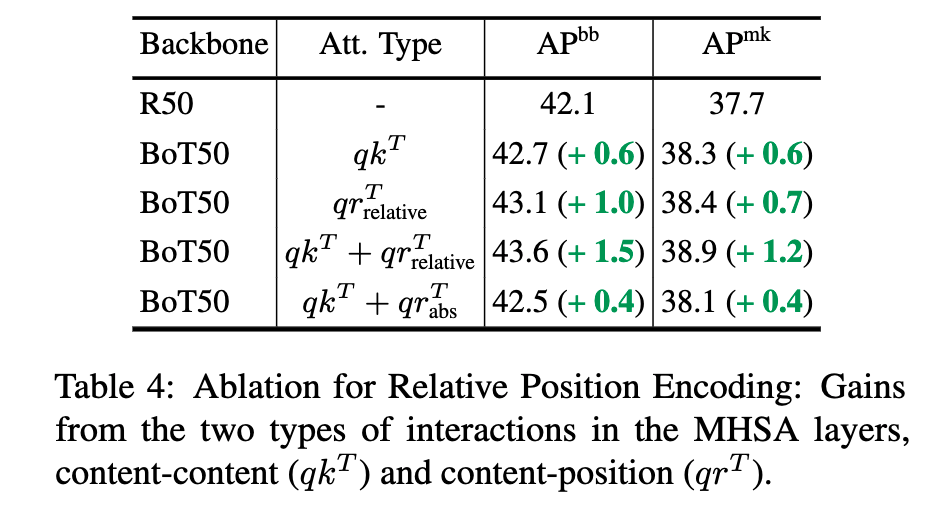
对于位置编码作者进行了实验,R50 指 ResNet50 作为 backbone。作者在 COCO 数据集进行目标检测上发现,如果不加位置编码直接使用 $qk^T$ 计算 Attention 有提升,但是直接使用位置编码计算的 Attention 得到的 gain 还要大一些 $qr_{relative}^T$。如果结合而这提升更大。做这也尝试了绝对位置编码(不知道是不是不可学习的意思哈),发现效果其实并不如相对位置编码。
注意到,上图说没有高亮蓝色框之后就是 Non-Local Layer(highlighted blue boxes,position encodings and the value projection),然而我去看他的引文[63] Non-local Neural Networks 原始论文,别人有 value projection 啊,所以我不知道是他理解错了还是我理解错了。
[53] Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representations. arXiv preprint arXiv:1803.02155, 2018.
[4] wan Bello, Barret Zoph, Ashish Vaswani, Jonathon Shlens, and Quoc V Le. Attention augmented convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 3286–3295, 2019.
[49] Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jonathon Shlens. Stand-alone self-attention in vision models. arXiv preprint arXiv:1906.05909, 2019.
[63] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7794–7803, 2018.
3. Bottleneck Transformer
在 Multi-Head Self-Attention 结构前后加上 $1 \times 1$ 卷积就得到了 Bottleneck Transformer。Bottleneck Transformer 和 ViT 中的 Transformer block 其实是有亲属关系的,他们不是差异很大的结构。作者在论文中首先提到说,具有 MHSA 的 ResNet botteneck 块可以被视作具有 bottleneck 结构,其他方面具有微小差异(例如残差结构,正则化层等)的 Transformer 块。We point out that it is not the case. Rather, ResNet botteneck blocks with the MHSA layer can be viewed as Transformer blocks with a bottleneck structure, modulo minor differences such as the residual connections, choice of normalization layers, etc。
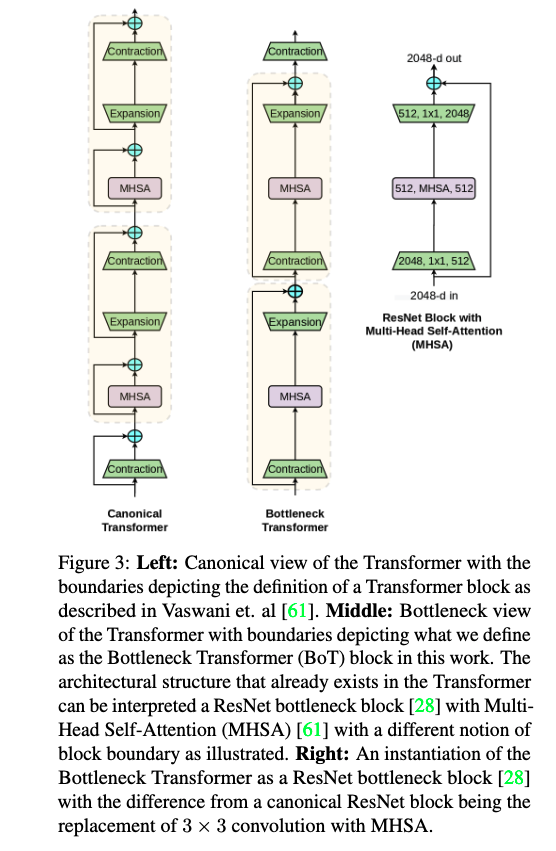
这怎么理解呢?我觉得是这样的,在 ViT 中的 Transformer 块中 MHSA 前后有残差连接,MHSA 之后经过了 MLP block,这里的 MLP block 其实就是两层全连接,第一层全连接对特征进行扩充,然后第二层全连接对特征进行压缩。MLP block 的输出也和输入进行了残差相加。这里忽略掉 Dropout 层。整个结构就如上图最左边一样。如果我们把 MLP block 拆开,然后 MHSA 放到 Expansion 之后会这么样呢?那就成了上图中间的模样。这个不就和 ResNet 中的 Bottleneck block 一样了嘛,不同在于 ResNet 在中间使用 $3 \times 3$ 卷积。那我们就换成 MHSA 好了。这也就是 BoT 诞生的初衷。
作者也相当坦诚啊:We note that the architectural design of the BoT block is not our contribution. Rather, we point out the relationship between MHSA ResNet bottleneck blocks and the Transformer with the hope that it improves our understanding of architecture design spaces [47, 48] for self-attention in computer vision. 作者的贡献不在于提出 BoTNet 的结构,而在于揭示它和 Transformer 原始结构的内在联系。
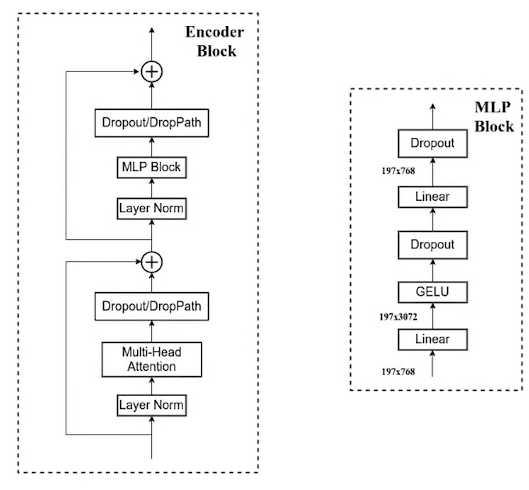
值得注意的是,既然把 MHSA 放到了 Resnet 中,原来的 LN 就被替换为了 BN。此外,在原始的 Transformer Block 中仅仅在 MLP block 中有一个 GELU 激活函数,而在 Bottleneck Transformer 中,有三个激活函数分别在一头一尾两个 $1 \times 1$ 卷积之后以及 MHSA 之后。这也是为了尽可能不修改原始的 ResNet 结构,只做最小的替换。至于说 BoTNet 使用 SGD,ViT 使用 Adam 等细节我们就略过了。
4. BoTNet 网络结构
BoTNet50 的网络结构如表所示,我们能够发现它其实就是把 ResNet50 最后一个阶段的 3 个 block 给替换上了 MHSA 结构。我们知道 Transformer 计算量是很大的,仅仅放在最后我们看到推理速度和计算操作个数都大幅增加了,尽管参数量少了点。这里有一个细节,c5 阶段第一个 block 是要进行下采样的,以前是 $3 \times 3$ 那里的 stride = 2。由于 MHSA 不支持下采样,现在呢在 MHSA 之后增加一个 $2 \times 2$ 的 average-pooling 层就行了(看源码知道的,作者并没有说是加在 MHSA 前还是后)。
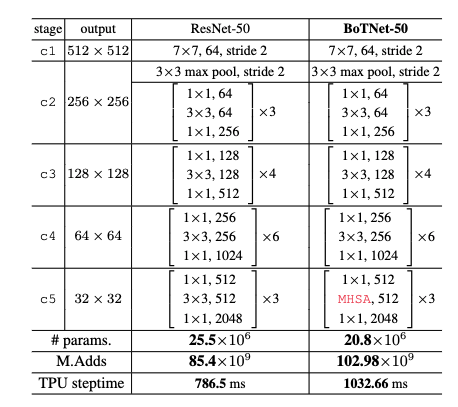
BoTNet50 是用来做 Backbone 的,用在 R-CNN 框架中。如果是做 ImageNet 分类,则 c5 其实不需要再进行下采样,否则特征图太小了。所以 c5 第一个 block 不进行 $2 \times 2$ 的 average-pooling 下采样的被称为 BoTNet50-S1 (stride = 1) 的意思。其实作者发现,在 c4 和 c5 都使用 BoT 模块效果更好,单单在 c4 加一个 BoT 都比 c5 用三个好,但是最终为什么还是用 BoT50 呢,考虑到计算量和速度以及性能的权衡,c4 加计算量太大了。

除去 BoT50 外,做这还能做到 BoT152 和 BoT200。再让 TPU 发展几年,这还不得到 BoT1k 啊。
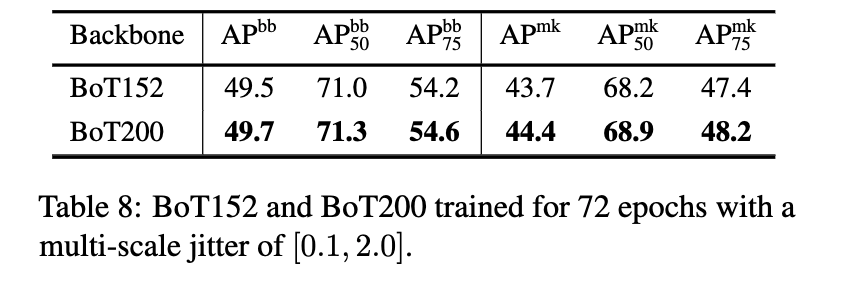
一般我不分析实验的,但今天还是站出来提出一个一直困扰我的疑惑!欢迎大家在评论区发表高见。
作者提到,BoTNet 对于小物体检测有提升,对于大物体没什么优势。但是 MHSA 是加在最后一个 stage 的,也就是最小分辨率的特征图上的。我们知道,层数越深尺度越小的特征图其实是被我们用来检测大物体的,而层数越浅尺度越大的特征图其实是被我们用来检测小物体的。BoTNet 在 c5 阶段扩大感受野到整个特征图,但是为什么提升了小物体的检测性能呢?DETR 就是因为将 Transformer 加到了 backbone 输出后面,对大特征图没有用,所以小物体检测也没有提升。而为什么 BoTNet 就能做到呢?
Significant boost from BoTNet on small objects (+2.4 Mask AP and +2.6 Box AP) (Appendix);
With visibly good gains on small objects in BoTNet, we believe there maybe an opportunity to address the lack of gain on small objects found in DETR, in future
5. 代码
代码出处见 此处。
import torch
import torch.nn as nn
import torch.nn.functional as F
def get_n_params(model):
pp=0
for p in list(model.parameters()):
nn=1
for s in list(p.size()):
nn = nn*s
pp += nn
return pp
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.rel_h = nn.Parameter(torch.randn([1, heads, n_dims // heads, 1, height]), requires_grad=True)
self.rel_w = nn.Parameter(torch.randn([1, heads, n_dims // heads, width, 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
content_content = torch.matmul(q.permute(0, 1, 3, 2), k)
content_position = (self.rel_h + self.rel_w).view(1, self.heads, C // self.heads, -1).permute(0, 1, 3, 2)
content_position = torch.matmul(content_position, q)
energy = content_content + content_position
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2))
out = out.view(n_batch, C, width, height)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1, heads=4, mhsa=False, resolution=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
if not mhsa:
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1, stride=stride, bias=False)
else:
self.conv2 = nn.ModuleList()
self.conv2.append(MHSA(planes, width=int(resolution[0]), height=int(resolution[1]), heads=heads))
if stride == 2:
self.conv2.append(nn.AvgPool2d(2, 2))
self.conv2 = nn.Sequential(*self.conv2)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion * planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion * planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
# reference
# https://github.com/kuangliu/pytorch-cifar/blob/master/models/resnet.py
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=1000, resolution=(224, 224), heads=4):
super(ResNet, self).__init__()
self.in_planes = 64
self.resolution = list(resolution)
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
# self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if self.conv1.stride[0] == 2:
self.resolution[0] /= 2
if self.conv1.stride[1] == 2:
self.resolution[1] /= 2
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # for ImageNet
if self.maxpool.stride == 2:
self.resolution[0] /= 2
self.resolution[1] /= 2
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2, heads=heads, mhsa=True)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Dropout(0.3), # All architecture deeper than ResNet-200 dropout_rate: 0.2
nn.Linear(512 * block.expansion, num_classes)
)
def _make_layer(self, block, planes, num_blocks, stride=1, heads=4, mhsa=False):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for idx, stride in enumerate(strides):
layers.append(block(self.in_planes, planes, stride, heads, mhsa, self.resolution))
if stride == 2:
self.resolution[0] /= 2
self.resolution[1] /= 2
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.maxpool(out) # for ImageNet
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
def ResNet50(num_classes=1000, resolution=(224, 224), heads=4):
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, resolution=resolution, heads=heads)
def main():
x = torch.randn([2, 3, 224, 224])
model = ResNet50(resolution=tuple(x.shape[2:]), heads=8)
print(model(x).size())
print(get_n_params(model))