稀疏表示学习(四)
本次主要学习资料是Duke大学Guillermo Sapiro教授的公开课——Image and video processing, by Pro.Guillermo Sapiro 课程。该课程可以在 Bilibili 上找到学习资源。
1. 稀疏建模实例:图像去噪、修复与去马赛克
基本想法很简单, $y$ 表示带噪声的图像(our data),$x$ 是我们正在寻找的。我们不打算处理整个图像,而是处理补丁(patch)。$R$ 是一个基本的简单二进制矩阵,它提取出以 $(i,j)$ 为中心的 patch,例如 $8\times 8$ 大小的 patch。注意这些 patch 之间是有重叠的,因为每次考虑的中心是挪向下一个。可见我们并非一次处理整个图像,而是处理所有重叠的 patches。
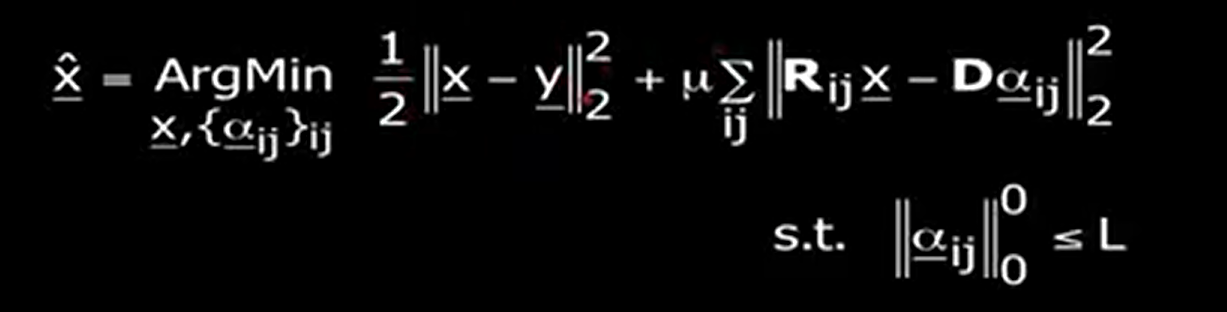
我们可以通过一个大型图片数据集进行离线学习字典,也可以使用图像本身学习使其适应于具体问题。也可以将通过离线学习出来的字典作为初始化,然后使用新图像对字典进行调整。

如果将字典学习考虑进来,则模型转化为下述形式:
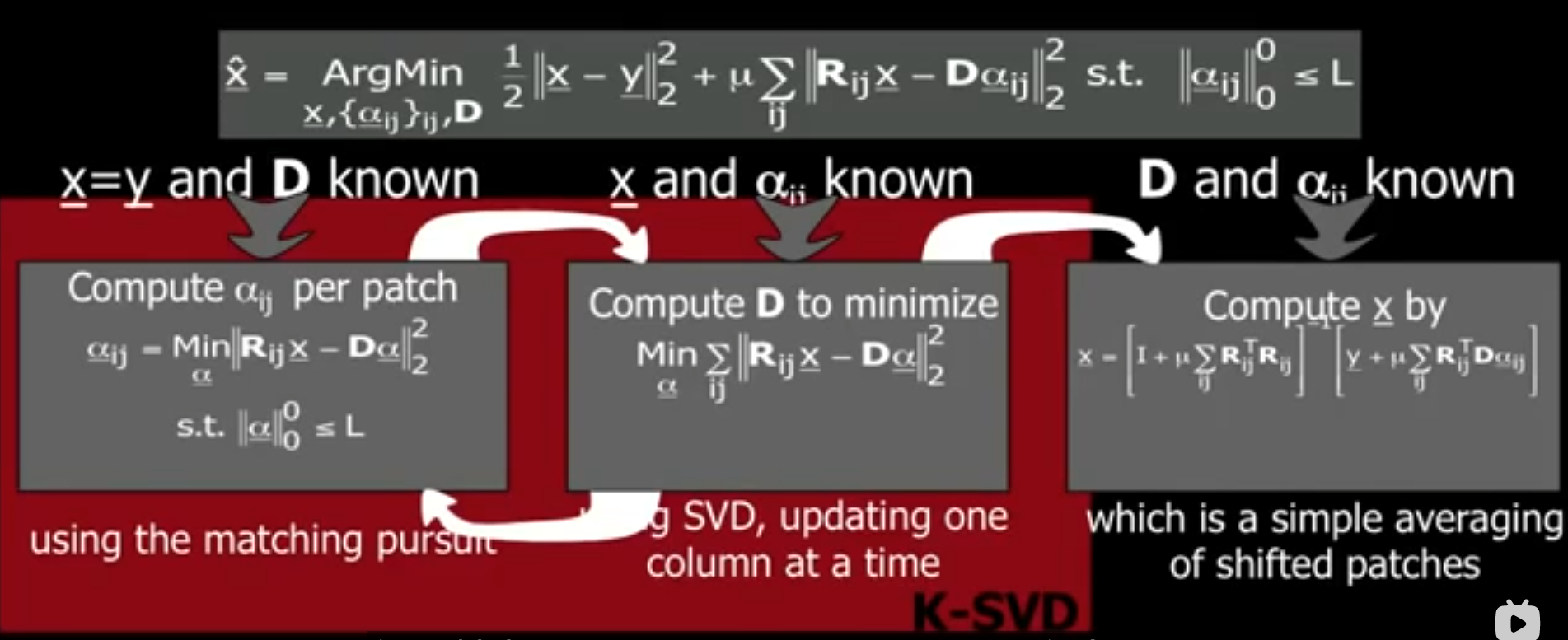
不断通过 K-SVD 算法循环优化字典及其稀疏表示。当字典和稀疏表示训练得差不多(收敛),最终出来的结果基本上就是 patches 的加权平均值。每个像素都被多个 patches 所考虑,如果 patch 的大小为 $8\times 8$ 的,则有 64 个 patches 考虑了同一个像素,除非该像素位于图像的边界附近。
灰度图像去噪实例
我们有一张原图(不可见的),一张添加高斯噪声后的噪声图(已知的),以及一个 $64 \times 256$ 大小的初始化过完备字典,这里考虑的patch 大小为 $8\times 8$ 。


最终可以通过这张已知的带噪图学习出一个字典,如下所示。通过两个方面减少了噪声:
- 将每个 patch 投射到空间中并使用稀疏编码
- 平均化 patch
彩色图像去噪实例
主要困难是定义不同彩色通道 R G B 之间的关系。一种最简单的解决方法是考虑一个 3D patch,即大小为 $8 \times 8 \times 3$。


Image Inpating 实例
去除原始图像80%的信息,再进行恢复,这个和压缩感知有关,在后续章节中会进行学习讨论。尽管我们只有 20% 的像素,我们也能进行很好的重建。


同样也可以做到删除某些像素,例如去文字,去雨等等。

Video Inpainting 实例
我们可以单独完成每一帧的 Inpainting,也可以进行实物 patch,即在 XY 和时间轴 T 三个维度进行讨论,可以将三帧或者五帧合到一起等等。

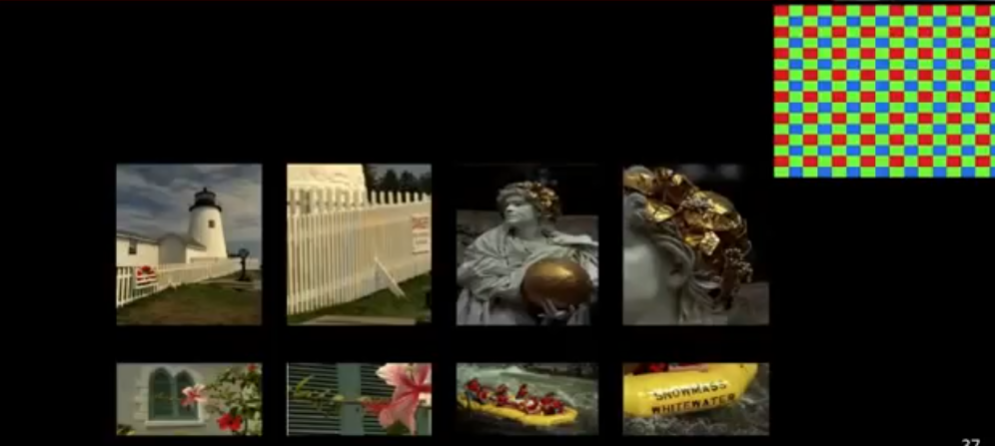
去马赛克实例 Demosaicing
这个去马赛克和去除图像中的马赛克不一样,这是从 RGGB 原始信号对图像进行恢复,大多数相机无法同时获取到一个像素点上红色、绿色和蓝色的强度值,只能获取其中一个。类似 Inpainting,不过每个像素点上仅仅有 R 或 G 或 B 的强度值,而前者即使整个像素缺失了也能进行恢复。通过 $n \times n \times 3$ 的 patch 来进行学习。
2. 压缩感知简述 Compressed Sensing
压缩感知基本上是使用一些我们已经学习过的概念,但是它的目标不是建模表示信号的信号,而是提供新的采样或者新的感知范式。
假设信号 $x$ 可以通过非常稀疏的表示 $a_0$ 进行重建,$x = Da_0$,其中 $D$ 是一个字典。
压缩感知想要的是,我们考虑在上式上乘上一个矩阵 $Q$,然后可以减少行数。$Q$ 有 $N$ 列,但是少于 $N$ 行,这就是压缩的来源。

$Q$ 和 $D$ 的乘积其实可以看成一个新的字典 $\bar{D}$。最终得到的 $\bar{x}$ 并不等于 $x$,而是等于比 $x$ 更短的的有意义的向量。此时我们有 $\bar{D}$ 和 $\bar{x}$ ,来计算 $\alpha$ 就和以前是一样的。然后我们通过 $D\alpha$ 就可以实现对 $x$ 的恢复重建。

压缩感知必须要保证这个恢复是可能的。